多智能体 — 让 Agent 学会分工协作
"多 Agent"大概是 AI 领域目前最被高估的概念之一。
每次看到"多智能体协作完成复杂任务"的 demo,我都会想:你确定这不是一个 Agent 跑三遍、中间加了几条 system prompt 就能搞定的事吗?
但话说回来,在做 BareAgent 的过程中,确实遇到了一些场景让我觉得"拆分 Agent"是有实际价值的。核心价值不在于"协作",而在于隔离。
子智能体:隔离的消息上下文
最先实现的不是团队系统,而是子智能体。动机很实际:主 Agent 在处理一个大任务时,中间需要做一个"探索性的小任务"——比如搜索一下代码库、搞清楚某个模块的结构。
如果在主循环里做这件事,探索过程的几十条消息(文件内容、搜索结果等)会永久地留在对话历史里,挤占上下文窗口。但如果拉一个子智能体出来做,探索结束后返回一段摘要文本,主循环只需要保留这段摘要就行。
def run_subagent(provider, task, tools, handlers, permission, ...):
if current_depth > max_depth:
return f"Subagent refused: recursion depth {current_depth} exceeds limit {max_depth}."
resolved_type = resolve_agent_type(agent_type, default_name=default_agent_type)
child_permission = _build_child_permission(permission, resolved_type, background)
# 独立消息历史
messages = []
if resolved_system_prompt.strip():
messages.append({"role": "system", "content": resolved_system_prompt})
messages.append({"role": "user", "content": task})
return agent_loop(
provider=provider,
messages=messages, # 全新的消息列表!
tools=filtered_tools,
handlers=child_handlers,
permission=child_permission,
max_iterations=resolved_type.max_turns,
)
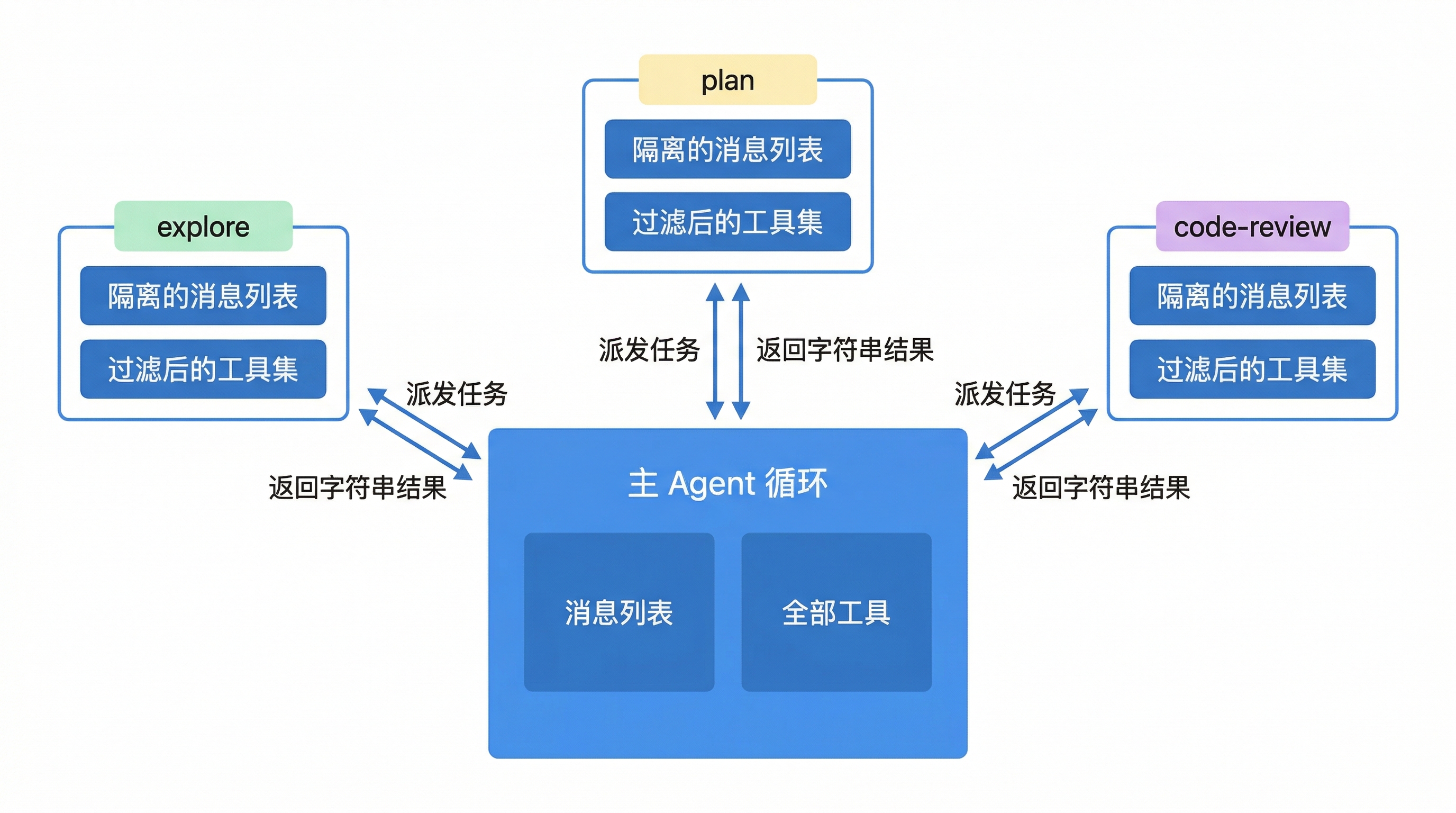
关键点:子智能体有自己的 messages 列表。它不继承父级的对话历史,也不会把自己的中间过程写回父级。父级拿到的只是最终返回的字符串。
这种隔离对上下文管理的帮助是巨大的。我实测过,一个涉及代码探索的任务,如果不拆子智能体,主循环的消息在 20 轮左右就会膨胀到需要压缩的程度。拆了之后,探索部分在子智能体里自行压缩,主循环的上下文保持精简。
AgentType:用冻结数据类定义"角色"
光有消息隔离还不够。不同用途的子智能体需要不同的能力限制。比如一个"探索"Agent 就不应该能写文件。
BareAgent 用 AgentType 冻结数据类来定义这些角色:
@dataclass(frozen=True, slots=True)
class AgentType:
name: str
description: str
system_prompt: str = ""
tools: list[str] | None = None # 白名单
disallowed_tools: list[str] | None = None # 黑名单
max_turns: int = 200
allow_nesting: bool = True
permission_mode: PermissionMode | None = None
当前内置了四种类型:
| 类型 | 能做什么 | 不能做什么 | 最大回合 |
|---|---|---|---|
general-purpose |
全量工具 | 无限制 | 200 |
explore |
读文件、搜索 | 写文件、bash、再嵌套 | 50 |
plan |
读文件、搜索 | 写文件、bash、再嵌套 | 50 |
code-review |
读文件、搜索 | 写文件、bash、再嵌套 | 50 |
后三种共享一组"只读默认值":
_READ_ONLY_DEFAULTS = {
"disallowed_tools": ["write_file", "edit_file", "bash", "subagent"],
"max_turns": 50,
"allow_nesting": False,
"permission_mode": PermissionMode.PLAN,
}
这里有一个双重保险的设计:工具过滤先移除 write_file、edit_file、bash、subagent,然后权限模式再设成 PLAN。即使有其他高风险工具(比如 task_update)没被工具过滤移除,PLAN 权限也会在执行时拦住它。
递归深度控制
allow_nesting=False 意味着 explore 子智能体不能再调 subagent。这防止了"探索 Agent 再拉起探索 Agent 再拉起探索 Agent"的递归爆炸。
即使对于 general-purpose(allow_nesting=True),也有硬性的递归深度限制:
if current_depth > max_depth:
return f"Subagent refused: recursion depth {current_depth} exceeds limit {max_depth}."
默认 max_depth=3,意味着最多套三层。三层在实践中已经很深了,大多数有用的嵌套只到两层。
工具过滤的实现
过滤逻辑分两步:
def filter_tools(all_tools, agent_type):
allowed = set(agent_type.tools) if agent_type.tools is not None else None
denied = set(agent_type.disallowed_tools) if agent_type.disallowed_tools is not None else None
strip_nesting = not agent_type.allow_nesting
def _keep(tool):
name = tool.get("name")
if allowed is not None and name not in allowed:
return False
if denied is not None and name in denied:
return False
if strip_nesting and name == "subagent":
return False
return True
return [t for t in all_tools if _keep(t)]
先按白名单/黑名单过滤,再根据 allow_nesting 决定是否移除 subagent。Handler 的过滤更简单——只保留在过滤后 schema 里仍存在的同名 handler。
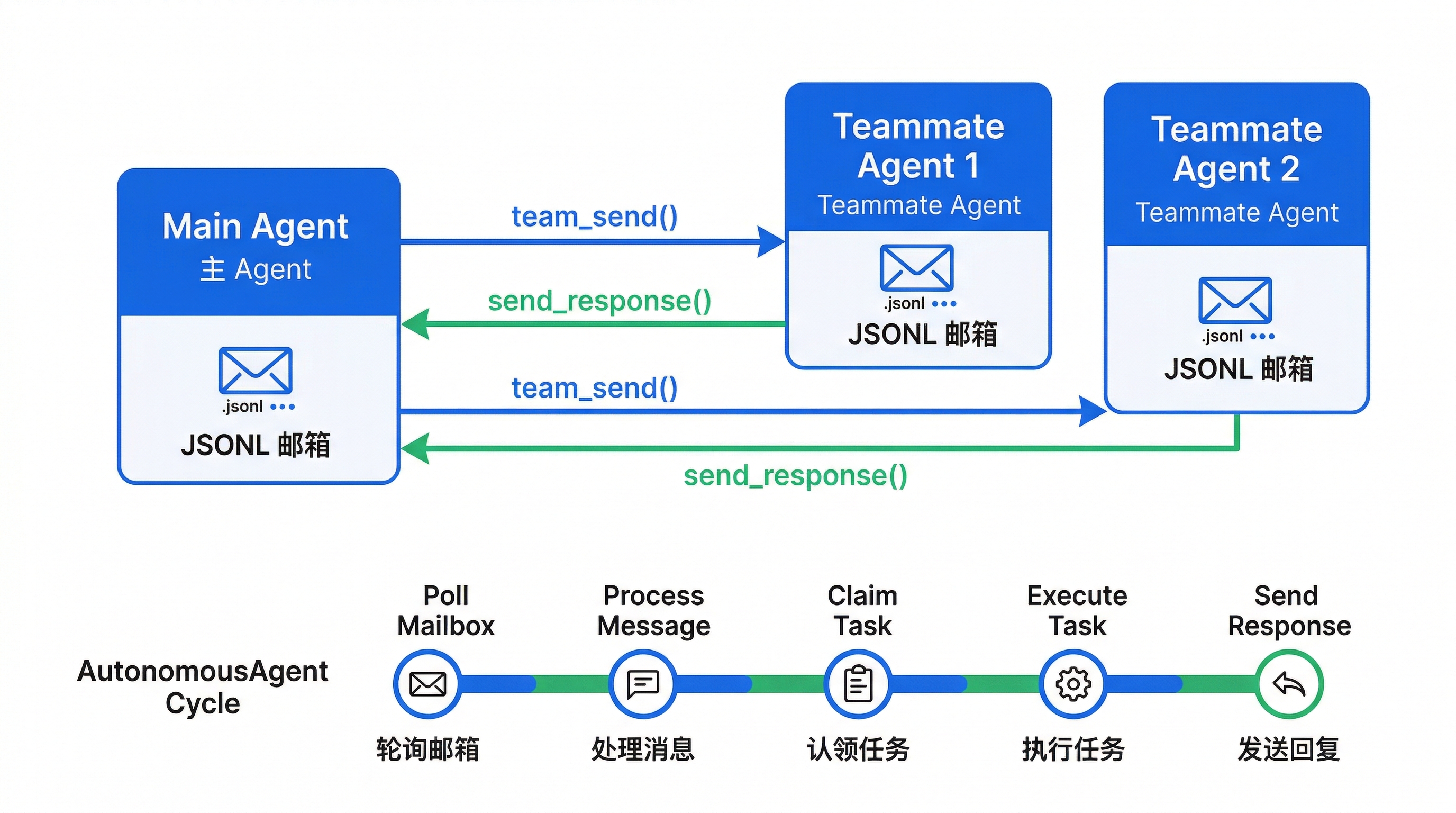
团队系统:基于 JSONL 邮箱的消息传递
子智能体是"一次性任务"——拉起来、做完、返回结果。但有些场景需要长期运行的 Agent,比如一个持续做代码审查的"队友"。
这就是 BareAgent 团队系统的用武之地。不过先说清楚:这套东西不是 Kubernetes,也不是消息队列。它本质上是一组"基于 JSONL 文件的邮箱"。
.mailbox/
main.jsonl # 主 Agent 的邮箱
reviewer.jsonl # 审查员的邮箱
tester.jsonl # 测试员的邮箱
每次发消息就是在目标 agent 的文件末尾追加一行 JSON:
class MessageBus:
def send(self, msg):
resolved = self._prepare_message(msg)
self._append(resolved.to_agent, resolved)
return resolved.id
def _append(self, agent_name, msg):
mailbox_path = self.ensure_mailbox(agent_name)
line = json.dumps(msg.to_dict(), ensure_ascii=False)
with self._lock_for(agent_name):
with mailbox_path.open("a", encoding="utf-8") as file:
file.write(line + "\n")
为什么用 JSONL 文件而不是内存队列?两个原因:
- 天然持久化 — 进程崩了消息不丢
- 天然审计 —
cat .mailbox/reviewer.jsonl就能看到完整通信历史
这种"每个 agent 一个文件、追加写入"的模型,和消息队列比起来显然很粗糙。但对一个终端工具来说,不需要引入 Redis 或者 RabbitMQ 的复杂度就能实现基本的 Agent 间通信,已经够用了。
读取语义
读取邮箱使用游标模式:
def receive(self, agent_name, since_id=None):
# since_id=None → 从头读
# since_id 存在 → 从该消息之后开始返回
配合 wait_for_message()(基于条件变量),轮询效率还不错——不需要每次都从头扫整个文件。
AutonomousAgent:空闲-轮询-认领循环
长期运行的队友由 AutonomousAgent 表示,它的主循环逻辑简单但有效:
def run(self):
while not self._shutdown:
# 1. 先看邮箱有没有新消息
incoming = self.bus.receive(self.name, since_id=self._last_seen_id)
if incoming:
self._last_seen_id = incoming[-1].id
self._handle_messages(incoming)
continue
# 2. 没有消息,看有没有 ready task 可以认领
if self.task_manager is not None:
ready_tasks = self.task_manager.get_ready_tasks()
for task in ready_tasks:
claimed = self._claim_task(task)
if claimed:
self._execute_task(claimed)
break
else:
time.sleep(self.poll_interval)
continue
# 3. 啥也没有,睡一会
time.sleep(self.poll_interval)
优先级很明确:邮箱消息 > 任务队列 > 空闲等待。
任务认领用的是乐观锁:
def _claim_task(self, task):
try:
return self.task_manager.update(
task.id, status="in_progress", expected_status="pending"
)
except ValueError:
return None # 别人抢先了
如果多个 Agent 同时看到同一个 ready task,只有第一个成功更新状态的能认领成功。其他的 update() 会发现状态已经不是 pending 了,返回 None,继续找下一个任务。
SHUTDOWN 协议
关闭队友不是直接 kill 线程,而是发一条 SHUTDOWN 协议消息:
if protocol == Protocol.SHUTDOWN:
self._shutdown = True
break
Agent 在下一轮循环检查时看到 _shutdown=True 就优雅退出。这比强行终止线程安全得多。
一个小细节:构造 AutonomousAgent 时,会把 _last_seen_id 初始化为当前邮箱的最新消息 id。这样启动前遗留在邮箱里的旧 SHUTDOWN 消息不会被重新消费——否则 agent 一起动就立刻停掉了。
协议封装
消息传递的上层是 ProtocolFSM,它负责把普通消息包装成协议格式:
def encode_protocol_content(protocol, content):
return json.dumps({"protocol": protocol.value, "content": content})
当前只有两个协议:PLAN_APPROVAL(审批计划)和 SHUTDOWN(关闭)。名字叫 FSM(状态机),但当前实现更准确地说是一个"带协议标签的请求-响应 helper"。
wait_response() 采用"轮询 + 条件变量"的混合实现——不是纯忙等,也不是纯阻塞,而是在短轮询间隙等待条件变量唤醒:
def wait_response(self, msg_id, timeout=60):
deadline = time.monotonic() + timeout
while time.monotonic() < deadline:
messages = self.bus.receive(self.agent_name, since_id=cursor)
for message in messages:
if message.msg_type == "response" and message.in_reply_to == msg_id:
return message
remaining = deadline - time.monotonic()
self.bus.wait_for_message(self.agent_name, timeout=min(remaining, 0.5))
return None
什么场景才真正需要多 Agent
回到文章开头的问题:多 Agent 什么时候有用?
根据我实际使用 BareAgent 的经验:
子智能体(subagent):经常用,尤其是代码探索。"帮我看看这个模块的结构"、"搜一下所有用到这个函数的地方"——这类任务拆成子智能体能有效控制上下文膨胀。
团队系统:偶尔用,主要场景是"一边做主任务一边让另一个 Agent 持续跑测试"。但说实话,大多数时候直接在主循环里手动切换任务就够了。
我的结论是:Agent 系统最有价值的"多"不是"多个 Agent 同时跑",而是"同一个循环能灵活地委派子任务并控制上下文"。
子智能体机制(隔离消息 + 类型控制 + 递归限制)的投入产出比远高于完整的团队通信系统。如果你也在做 Agent 系统,建议先把子智能体做好,团队系统可以晚些再加。
延伸思考
业界的多 Agent 方案大致分几派:
- 对话式(如 AutoGen):多个 Agent 在一个共享对话里轮流发言
- 图式(如 LangGraph):预定义好 Agent 之间的工作流图
- 邮箱式(如 BareAgent):各自独立运行,通过消息总线通信
对话式最简单但最不可控——你很难限制某个 Agent 的能力范围。图式最可控但最僵化——修改流程意味着修改图结构。邮箱式是折中方案——Agent 之间松耦合,但通信成本高(要等轮询周期)。
我越来越觉得,"多 Agent"这个方向的真正价值可能不在于让 Agent 互相协作,而在于让用户能用自然语言动态地组织 Agent 团队。现在的实现都还太"写死"了——注册队友、配置角色、定义工具白名单,这些如果能让用户在对话中动态完成,多 Agent 的体验会质变。
评论