对话越来越长怎么办 — Agent 的记忆压缩策略
Agent 系统有一个不那么光鲜但极其实际的问题:对话越来越长了怎么办?
一个 Agent 在做稍微复杂点的任务时,轻轻松松就能产生几十轮工具调用。每次 read_file 返回几百行代码,每次 grep 返回几十条搜索结果,每次 bash 返回一屏命令输出。这些东西累积在消息历史里,token 数很快就会膨胀到让你心疼钱包的程度。
更实际的问题是 LLM 的上下文窗口有限。即使用最新的 200k 窗口模型,真正有效利用的通常不超过一半——太长了模型的注意力会退化,开始忽略中间的内容。
BareAgent 的解决方案是两阶段压缩:先做廉价的截断,不够再做 LLM 驱动的摘要。
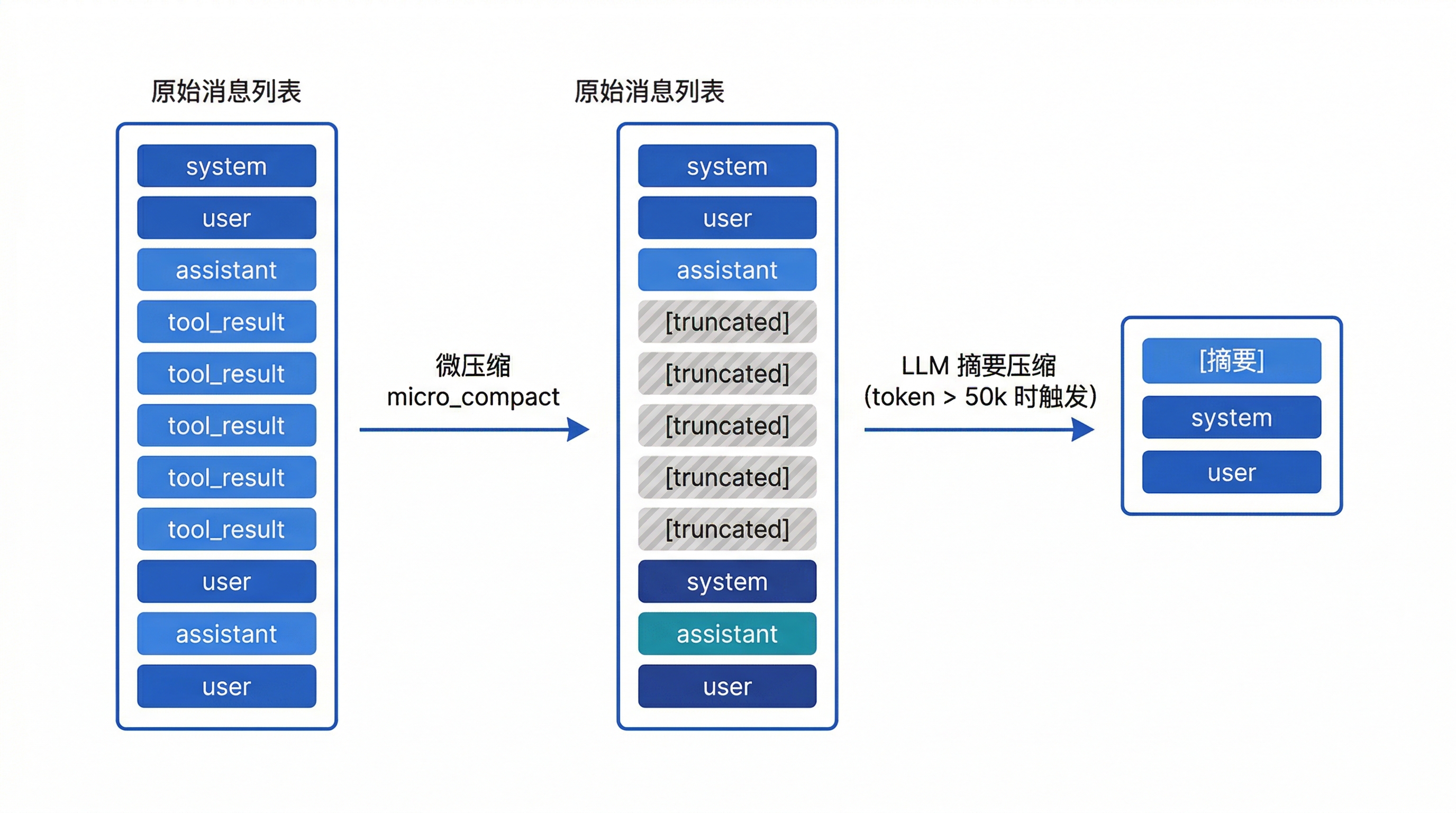
第一阶段:微压缩
微压缩的思路很朴素:旧的工具结果没人看了,截掉。
想想看,10 轮之前 read_file 返回的那 300 行代码,模型大概率不会再回头看了。与其让它占着上下文窗口,不如用一句话概括:"之前读了个文件,300 行,内容已截断。"
def _micro_compact(messages, keep_recent=3):
tool_name_by_id = _collect_tool_names(messages)
tool_result_indices = [
i for i, msg in enumerate(messages) if _message_has_tool_results(msg)
]
# 保留最近 3 条,其余截断
compact_indices = set(tool_result_indices[:-keep_recent])
for index in compact_indices:
message = messages[index]
for block in message.get("content", []):
if block.get("type") != "tool_result":
continue
original_text = block.get("content", "")
if original_text.startswith("[truncated:"):
continue # 已经截断过了
tool_name = tool_name_by_id.get(block.get("tool_use_id", ""), "unknown")
block["content"] = f"[truncated: {tool_name} result, {len(original_text)} chars]"
几个设计选择:
保留最近 3 条工具结果。不是 1 条,不是 5 条,是 3 条。这个数字是实测出来的——太少了模型在多步操作时会丢失最近的上下文,太多了截断效果不明显。
只截断工具结果,不动其他内容。用户消息、assistant 文本、system 消息都不碰。这些通常体积不大但语义密度高,截掉会丢信息。
原地修改消息列表。不创建新副本,直接改。这是个性能考量——消息列表可能很大,深拷贝一份代价不小。
幂等处理。已经被截断的结果(以 [truncated: 开头的)不会再截断一次。这让微压缩可以安全地每轮都跑。
保留工具名和原始大小。截断后的文本长这样:
[truncated: bash result, 1204 chars]
模型看到这个可以知道"之前跑了个 bash 命令,结果有 1204 个字符,但已经被截断了"。这比完全空白要好——至少模型知道这个操作发生过。
微压缩每轮都会执行,不管 token 数有没有超过阈值。它几乎没有性能成本(就是遍历一下列表改几个字符串),但能持续把上下文保持在合理范围内。
第二阶段:完整压缩
如果微压缩之后 token 数仍然超过阈值,就需要动用更激进的手段了——让 LLM 把整段对话压缩成一段摘要。
class Compactor:
def __call__(self, messages, force=False):
_micro_compact(messages, keep_recent=3)
if not force and estimate_tokens(messages) <= self._threshold:
return
# 拆出最后一条用户消息
history, pending_user = _split_pending_user_turn(messages)
summary_source = [m for m in history if m.get("role") != "system"]
# 让 LLM 生成摘要
summary = self._provider.create(
messages=[
{"role": "system", "content": "你是上下文压缩助手,请总结关键信息..."},
{"role": "user", "content": "请总结以下对话:\n\n" + _serialize(summary_source)},
],
tools=[],
max_tokens=2000,
)
# 重建消息列表
system_msgs = [clone(m) for m in messages if m.get("role") == "system"]
messages.clear()
messages.extend(system_msgs)
messages.extend([
{"role": "user", "content": f"[Context Compressed]\n{summary.text}"},
{"role": "assistant", "content": "收到,我已理解之前的上下文,继续工作。"},
])
if pending_user:
messages.append(pending_user)
这个过程可以分解为几步:
1. 判断是否需要压缩
默认阈值是 50000 token。为什么是 50k?
- 太低(比如 20k)会导致频繁压缩,每次压缩都会丢信息
- 太高(比如 100k)会导致模型注意力退化、费用飙升
- 50k 大致是"模型还能有效利用大部分内容"的上限
当然,/compact 命令可以强制执行,不管当前 token 数多少。
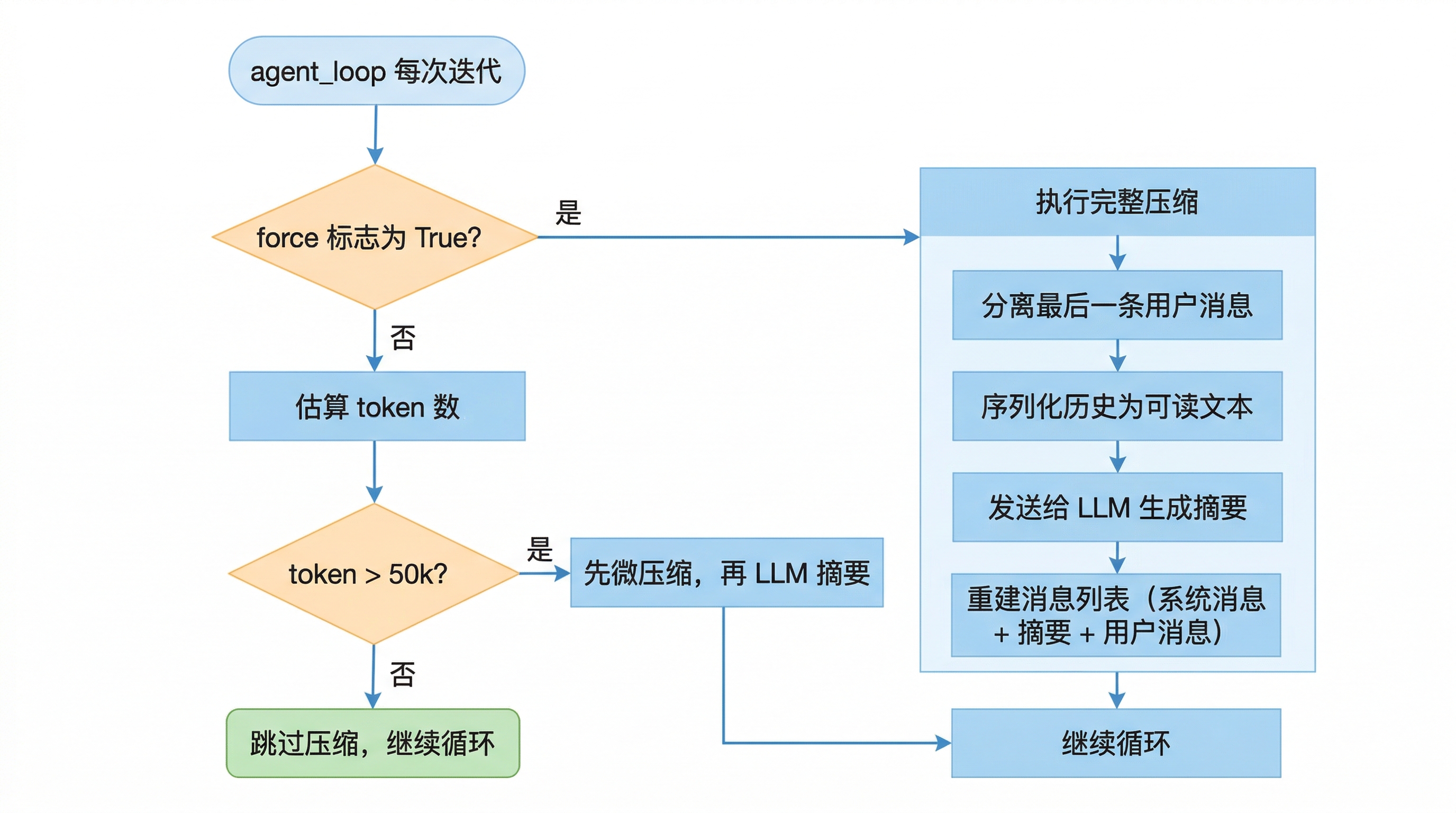
2. 拆出最后一条用户消息
在压缩之前,最后一条 role="user" 的消息会被暂时拆出来。理由很简单——这条消息是"当前还在处理的输入",把它压进摘要里的话,模型接下来就不知道自己正在回答什么问题了。
3. 序列化对话历史
摘要不是把原始 JSON 丢给模型,而是先转成一种更易读的格式:
[user]
请帮我读一下配置文件
[assistant]
[tool_use:read_file] {"file_path": "config.toml"}
[user]
[tool_result:read_file] 1: [provider]
2: name = "anthropic"
...
这种格式保留了角色、工具名、参数和结果的语义结构,同时比 JSON 更紧凑,模型也更容易理解。
4. 重建消息列表
压缩成功后,原消息列表被重写为:
[system 消息(全部保留)]
[user: "[Context Compressed]\n{摘要}"]
[assistant: "收到,我已理解之前的上下文,继续工作。"]
[刚才拆出来的最后一条 user 消息]
注意 system 消息全部保留——初始系统提示、技能清单、后台通知这些都不能丢。
5. 失败也没关系
如果摘要生成失败(provider 报错、超时等),压缩器只记一条 warning,不修改消息列表:
except Exception:
logger.warning("Context compression failed", exc_info=True)
return
这个"尽力做,失败不崩"的策略很重要。压缩是优化手段,不是关键路径。宁可让上下文继续膨胀,也不能因为压缩失败而丢失整个对话。
不装 tiktoken 也能估 token
判断是否触发压缩需要估算当前消息的 token 数。精确计算需要 tiktoken 之类的 tokenizer 库,但 BareAgent 想保持零额外依赖(除了 LLM SDK 本身),所以用了一个基于字符分类的启发式估算器:
def _estimate_text(text):
cjk = len(_CJK_PATTERN.findall(text))
ascii_alnum = len(_ASCII_ALNUM_PATTERN.findall(text))
whitespace = len(_WHITESPACE_PATTERN.findall(text))
other = len(text) - cjk - ascii_alnum - whitespace
return cjk * 1.5 + ascii_alnum * 0.25 + whitespace * 0.25 + other * 0.5
权重背后的逻辑:
- CJK 字符 × 1.5 — 中文一个字通常被拆成 1-2 个 token,取 1.5 是保守估计
- ASCII 字母数字 × 0.25 — 英文大约 4 个字符 1 个 token
- 空白 × 0.25 — 和英文类似
- 其他字符 × 0.5 — 标点符号、特殊字符的 token 效率不太确定,取中间值
这个估算器不精确,但一致性好——它总是偏向高估(宁可提前压缩也不要超窗口),而且足够快(纯正则匹配,不需要加载词表)。
估算器还支持递归结构——能处理嵌套的 block、工具调用参数等。这比简单地 json.dumps 之后数字符要准确一些:
def _estimate_value(value):
if isinstance(value, str):
return _estimate_text(value)
if isinstance(value, list):
return sum(_estimate_value(item) for item in value)
if isinstance(value, dict):
if value.get("type") == "tool_use":
return _estimate_text(value.get("name", "")) + _estimate_value(value.get("input"))
# ...递归处理其他字段
微压缩和完整压缩的叠加
一个实际的场景:
- 对话进行了 30 轮,微压缩持续截断旧工具结果
- token 估算仍然超过 50k(因为 assistant 文本和近期工具结果累积)
- 触发完整压缩
- 摘要模型看到的历史里,可能已经有不少
[truncated: ...]标记 - 摘要照常生成——被截断的信息就是丢了,但至少工具名还在,摘要能知道"之前做过什么"
这种叠加关系是自然的。微压缩先做"无损"(从上下文利用的角度看是低损)的瘦身,完整压缩再做"有损"的折叠。
子智能体的独立压缩
每个同步子智能体会创建自己的 Compactor:
compact_fn = Compactor(
provider=provider,
transcript_mgr=None, # 子智能体不保存 transcript
threshold=50_000,
)
这意味着:
- 子智能体有自己的压缩阈值和压缩状态
- 子智能体压缩不会影响父级的消息历史
- 子智能体的中间状态不会写入 transcript
这是上下文隔离的自然延伸——既然消息历史是独立的,压缩当然也是独立的。
不过团队系统里长期运行的 AutonomousAgent 当前没有接入压缩器(compact_fn=lambda _: None)。这是一个已知的局限——如果队友处理一个很长的任务,上下文会持续膨胀直到 token limit 报错。后续可能会加上。
压缩 vs RAG vs 滑动窗口
做上下文管理的时候,我考虑过几种不同的方案:
滑动窗口(保留最近 N 条消息,丢弃更早的):最简单,但太粗暴。Agent 可能在第 5 轮确定了一个关键架构决策,到第 50 轮时这个信息已经滑出窗口了,但它仍然是重要的上下文。
RAG(把历史消息存到向量库里,需要时检索):最灵活,但引入了额外的基础设施依赖和检索质量问题。对于一个终端工具来说太重了。而且 Agent 的上下文和文档检索不太一样——Agent 需要的是"之前做过什么、当前状态是什么",这种时序性的信息不太适合纯语义检索。
摘要压缩(BareAgent 的选择):折中方案。丢信息但有控制地丢——system 消息完整保留,近期工具结果完整保留,更早的历史通过 LLM 压缩成摘要。不需要额外基础设施,但依赖摘要模型的质量。
最终选了摘要压缩,因为它在"无额外依赖"和"不丢失关键信息"之间取得了可接受的平衡。
踩过的坑
压缩时机太早的问题。一开始阈值设得比较低(大约 20k),导致 Agent 在做复杂任务时频繁压缩。每次压缩都会丢失一些上下文,连续压缩几次之后模型就"忘了"自己之前在干什么。后来提到 50k 之后好了很多。
微压缩的 keep_recent 值。最开始设成 1,只保留最新的一条工具结果。结果发现模型经常需要回看前两三步的工具输出来做决策——比如先 grep 搜到文件,再 read 读内容,然后 edit 修改。如果 grep 结果在 edit 之前就被截断了,模型可能不记得搜到的是哪个文件。改成 3 之后这个问题基本消失了。
摘要的语言选择。system prompt 写的是"用中文总结"。如果不指定语言,摘要可能用英文写(因为对话中的代码和工具输出大部分是英文的),导致压缩后上下文里突然出现大段英文摘要,和用户的中文对话风格不一致。显式指定中文后,摘要和对话的衔接自然多了。
最后的思考
做完压缩系统之后,最深的感受是:上下文管理是 Agent 工程里最不性感但最影响体验的部分。
用户不会注意到你的压缩做得好——它就该是透明的。但用户一定会注意到压缩做得烂:Agent 突然"失忆"了、开始重复之前做过的事、或者突然不知道自己在干什么了。
理想的上下文管理应该像人类的记忆一样:重要的事情记得住,不重要的细节自然淡忘,但你要问起来还能大致想起"之前做过这件事"。BareAgent 的两阶段压缩离这个理想还有距离,但在工程上已经能支撑一个终端 Agent 稳定运行几十轮工具调用不翻车了。
评论