Agent 出了 bug 你怎么查 — 交互日志与实时调试
Agent 的 bug 和传统软件不一样。传统软件出了问题,你看 traceback、加断点、print 几下基本就能定位。但 Agent 的 bug 往往不是代码报错——代码跑得好好的,是模型做了一个莫名其妙的决策。
比如你让 Agent 改一个配置文件,它先 read_file 读了内容,然后突然决定去 grep 搜索一个完全不相关的东西,接着又 bash 跑了一个奇怪的命令。整个过程没有任何异常抛出,但结果就是不对。
你想搞清楚它为什么做了这个决策,就需要看它当时的完整上下文:发给模型的 messages 长什么样?tools 列表里有哪些工具?模型返回了什么?token 用了多少?这些信息,print 大法在几十轮交互面前根本不好使——你会淹没在几万行输出里。
BareAgent 的解决方案是一套 opt-in 的交互日志系统:每次 LLM 调用的完整 request 和 response 都以结构化 JSON 持久化到磁盘,同时通过事件推送支持实时查看。
为什么不用 Python logging
第一反应可能是"用标准库 logging 不就行了"。试过之后发现不太合适,原因有几个:
logging 面向"事件",Agent 调试需要面向"交互"。 一次 LLM 调用包含 request 和 response 两部分,它们是一个原子单位——你几乎不会只看 request 不看 response。但 logging 的模型是一条一条独立的日志记录,要把 request 和 response 关联起来需要额外的 correlation ID 机制。
文本格式不适合存储结构化数据。 messages 列表可能包含嵌套的 tool_use block、base64 图片、多层 content 结构。把这些东西 str() 之后塞进 log 文件,事后想解析回来基本不可能。
需要 session 隔离和序号排列。 Agent 可能同时跑多个 session(主智能体 + 子智能体),每个 session 的交互需要独立存储、按序号排列。logging 的 handler 体系做这个太绕了。
所以 BareAgent 自己实现了一个 InteractionLogger:
class InteractionLogger:
"""Persist complete LLM request/response payloads for a session."""
def __init__(
self,
log_dir: str | Path = ".logs",
session_id: str = "default",
*,
pretty: bool = True,
) -> None:
self._log_dir = Path(log_dir)
self._session_id = self._validate_session_id(session_id)
self._pretty = pretty
self._seq = 0
self._session_dir: Path | None = None
self._event_lock = threading.Lock()
self._event_subscribers: set[queue.Queue[dict[str, Any]]] = set()
核心就三个状态:日志目录、session ID、序号计数器。加上一个发布-订阅系统用于实时事件推送。
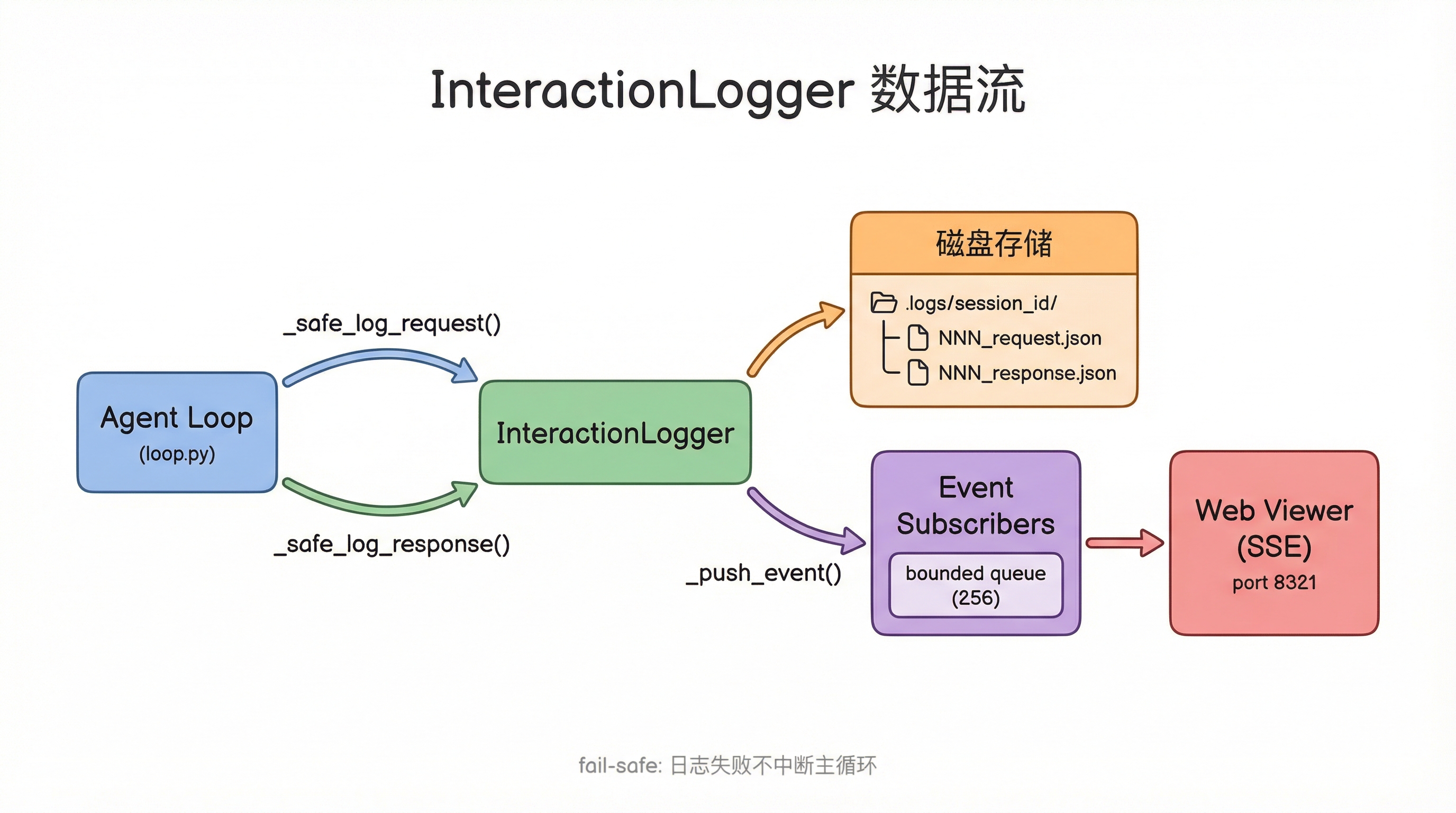
文件结构:一个 session 一个目录
日志的物理存储结构长这样:
.logs/
├── session-abc123/
│ ├── 000_request.json
│ ├── 000_response.json
│ ├── 001_request.json
│ ├── 001_response.json
│ └── 002_request.json ← response 可能因异常缺失
└── session-def456/
├── 000_request.json
└── 000_response.json
几个设计选择:
为什么用 JSON 文件不用数据库? 零依赖。.logs/ 目录可以直接 cat 查看、jq 过滤、cp 备份。不需要装 SQLite,不需要理解 schema,不需要写迁移脚本。对于一个终端工具来说,能用文件系统解决的事情就不要引入数据库。
为什么 request 和 response 分开存? 因为 response 可能不存在。如果 LLM 调用超时、网络断开、或者用户 Ctrl+C 中断,request 已经发出去了但 response 永远不会回来。分开存的话,你至少能看到"发了什么请求但没收到回复",这本身就是有价值的调试信息。
为什么用三位数序号前缀? 000_request.json 而不是 request_0.json。这样文件系统的默认排序就是时间顺序,ls 一下就能看到完整的交互时间线。三位数支持到 999 轮,对绝大多数 session 来说足够了。
与 Agent Loop 的集成:fail-safe 优先
日志系统和 agent loop 的集成点在 loop.py 里。这里有一个核心原则:日志失败绝不中断 agent 循环。
想想看,如果因为磁盘满了、权限不对、或者 JSON 序列化出了问题,导致日志写入失败,然后整个 Agent 就崩了——这完全不可接受。日志是辅助功能,不是关键路径。
所以集成用了两个 wrapper 函数:
def _safe_log_request(
*,
interaction_logger,
messages, tools, provider, console,
) -> tuple[int | None, float]:
if interaction_logger is None:
return None, 0.0
try:
log_seq = interaction_logger.log_request(
messages, tools,
provider_info=_provider_info(provider),
)
except Exception as exc:
_report_log_failure(console, "request", exc)
return None, 0.0
return log_seq, time.monotonic()
def _safe_log_response(
*,
interaction_logger, log_seq, console,
**kwargs,
) -> None:
if interaction_logger is None or log_seq is None:
return
try:
interaction_logger.log_response(log_seq, **kwargs)
except Exception as exc:
_report_log_failure(console, "response", exc)
几个值得注意的点:
interaction_logger is None 的短路判断。 日志是 opt-in 的,大部分时候 logger 就是 None,这个判断让零开销成为默认。
time.monotonic() 计时。 request 记录时拿一个起始时间戳,response 记录时算 duration。用 monotonic 而不是 time.time(),因为系统时钟可能被 NTP 调整,monotonic 保证单调递增。
异常只报告不抛出。 _report_log_failure 只是在控制台打一行提示,不会 raise。即使日志完全坏掉了,Agent 照常工作。
在 agent loop 的主循环里,集成点长这样:
log_seq, log_started_at = _safe_log_request(
interaction_logger=interaction_logger,
messages=messages, tools=tools,
provider=provider, console=console,
)
try:
response = _invoke_provider(provider, messages, tools, ...)
except BaseException as exc:
_safe_log_response(
interaction_logger=interaction_logger,
log_seq=log_seq, console=console,
duration_ms=(time.monotonic() - log_started_at) * 1000,
error=str(exc) or type(exc).__name__,
)
raise
_safe_log_response(
interaction_logger=interaction_logger,
log_seq=log_seq, console=console,
text=response.text, thinking=response.thinking,
tool_calls=_serialize_tool_calls(response.tool_calls),
input_tokens=response.input_tokens,
output_tokens=response.output_tokens,
duration_ms=(time.monotonic() - log_started_at) * 1000,
)
注意 except BaseException——即使是 KeyboardInterrupt,也要尝试记录错误信息再 raise。这样你事后查日志能看到"这次调用被用户中断了",而不是一个孤零零的 request 文件没有对应的 response。
为什么不用 decorator 或 middleware? 考虑过,但 agent loop 的调用链不是简单的"调用前/调用后"——它需要在 request 阶段拿到 seq 和时间戳,在 response 阶段(包括异常路径)传回去。decorator 模式在这种"两阶段关联"的场景下反而更绕。直接在调用点写两行 wrapper 调用,意图最清晰。
实时事件推送:线程安全的发布-订阅
光把日志写到磁盘还不够。调试的时候你经常想"实时看到 Agent 正在干什么",而不是等它跑完了再去翻文件。
InteractionLogger 内置了一个轻量的发布-订阅机制。每次 log_request 或 log_response 被调用时,除了写文件,还会向所有订阅者推送一个事件通知:
def _push_event(self, event_type, seq, payload):
event = {
"event": event_type,
"session_id": self._session_id,
"seq": seq,
"timestamp": payload.get("timestamp"),
}
with self._event_lock:
subscribers = tuple(self._event_subscribers)
for event_queue in subscribers:
self._publish_event(event_queue, event)
订阅者通过 subscribe_events() 拿到一个 bounded queue,通过 unsubscribe_events() 退订。这里有一个关键的设计决策——当 queue 满了怎么办?
def _publish_event(self, event_queue, event):
try:
event_queue.put_nowait(event)
return
except queue.Full:
pass
# queue 满了:丢掉最旧的事件,腾出空间
try:
event_queue.get_nowait()
except queue.Empty:
return
try:
event_queue.put_nowait(event)
except queue.Full:
return
策略是丢旧保新:如果消费者来不及处理,就丢掉最旧的事件,把最新的塞进去。
为什么不阻塞等待?因为 _push_event 是在 agent loop 的主线程里调用的。如果某个慢消费者(比如一个网络不好的浏览器)导致 queue 满了,阻塞等待就意味着整个 Agent 停下来等一个调试工具——这完全本末倒置。
为什么不无限扩容?因为内存会爆。一个忘记 unsubscribe 的消费者会导致 queue 无限增长。bounded queue(默认 256 条)给了一个明确的上限。
这个 trade-off 的本质是:调试信息的完整性 < Agent 主循环的稳定性。丢几条事件通知不影响调试(磁盘上的完整日志还在),但阻塞主循环会直接影响用户体验。
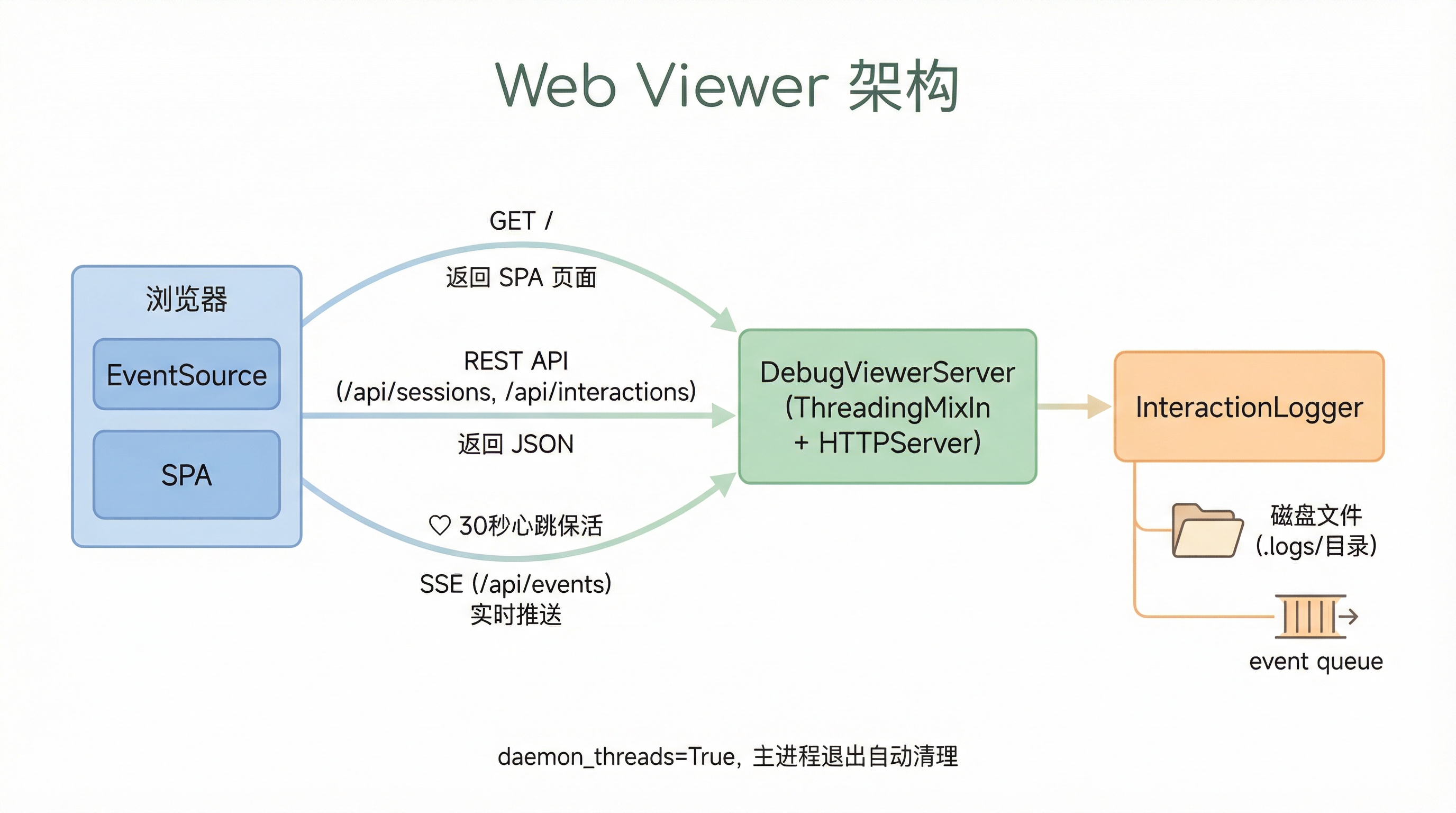
Web Viewer:内置的调试 UI
有了日志文件和事件推送,下一步自然是做一个可视化界面。BareAgent 内置了一个极简的 Web Viewer——不需要装任何前端依赖,一个 Python 文件搞定。
架构很直接:ThreadingMixIn + HTTPServer,提供三类接口:
- SPA 页面 — 根路径
/返回一个内嵌的 HTML 文件 - REST API —
/api/sessions、/api/sessions/<id>、/api/interactions/<id>/<seq>提供数据 - SSE 实时推送 —
/api/events端点,浏览器通过 EventSource 订阅
class DebugViewerServer(ThreadingMixIn, HTTPServer):
daemon_threads = True
allow_reuse_address = True
def __init__(self, logger, port=8321, host="127.0.0.1"):
self.logger = logger
super().__init__((host, port), DebugViewerHandler)
SSE 端点是最有意思的部分:
def _serve_sse(self):
self.send_response(200)
self.send_header("Content-Type", "text/event-stream")
self.send_header("Cache-Control", "no-cache")
self.send_header("Connection", "keep-alive")
self.end_headers()
event_queue = self.server.logger.subscribe_events()
try:
while True:
try:
event = event_queue.get(timeout=30)
payload = json.dumps(event, ensure_ascii=False, default=str)
self.wfile.write(f"data: {payload}\n\n".encode("utf-8"))
except Empty:
self.wfile.write(b": heartbeat\n\n")
self.wfile.flush()
except (BrokenPipeError, ConnectionResetError, OSError):
return
finally:
self.server.logger.unsubscribe_events(event_queue)
几个细节:
30 秒心跳。 SSE 连接如果长时间没有数据,中间的代理或浏览器可能会断开。每 30 秒发一个 SSE 注释(: heartbeat\n\n)保活。
finally 块 unsubscribe。 浏览器关闭标签页时不会优雅地关闭 SSE 连接,服务端会收到 BrokenPipeError。finally 确保无论怎么退出都会清理订阅,避免 queue 泄漏。
daemon_threads = True。 服务器线程是守护线程,主进程退出时自动清理,不会阻止程序结束。
用户通过 REPL 命令 /log serve 启动 viewer,/log open 直接在浏览器里打开。
安全:路径遍历防护和 opt-in 设计
日志系统涉及文件读写,安全不能马虎。
最大的风险是路径遍历。session_id 直接用于构造文件路径(.logs/<session_id>/),如果不校验,攻击者可以传入 ../../etc/passwd 之类的值来读取任意文件。
BareAgent 的防护很严格:
def _validate_session_id(self, session_id):
value = str(session_id)
if value in {"", ".", ".."}:
raise ValueError("Session ID must be a single relative path segment.")
if "/" in value or "\\" in value:
raise ValueError("Session ID must not contain path separators.")
posix_path = PurePosixPath(value)
windows_path = PureWindowsPath(value)
if posix_path.is_absolute() or windows_path.is_absolute():
raise ValueError("Session ID must not be an absolute path.")
if len(posix_path.parts) != 1 or len(windows_path.parts) != 1:
raise ValueError("Session ID must be a single path segment.")
return value
同时检查 POSIX 和 Windows 两种路径格式——因为 BareAgent 是跨平台的,不能只防一种。
另一个安全设计是 opt-in。日志默认是关闭的,你需要显式传入 InteractionLogger 实例才会开始记录。这意味着:
- 正常使用时不会意外地把敏感对话写到磁盘
- 不会在用户不知情的情况下占用磁盘空间
- 环境变量可以覆盖,方便 CI 环境临时开启调试
踩过的坑
JSON 序列化边界。 tool_calls 里可能包含不可 JSON 序列化的对象——比如自定义的 dataclass、bytes 类型的参数。一开始直接 json.dumps 会炸。解决方案是加一个 default=str 兜底:
json.dumps(payload, ensure_ascii=False, indent=2, default=str)
不优雅,但实用。default=str 意味着"实在不知道怎么序列化的东西,就 str() 一下"。你可能会丢失一些类型信息,但至少不会因为序列化失败而丢掉整条日志。
SSE 连接泄漏。 早期版本没有 finally 块做 unsubscribe。浏览器直接关闭标签页时,服务端的 SSE 循环会因为 BrokenPipeError 退出,但 event_queue 还留在订阅者集合里。结果就是 _publish_event 每次都往一个没人消费的 queue 里塞事件,queue 满了之后每次推送都要先 get 再 put,白白浪费 CPU。加了 finally 之后问题消失。
bounded queue 的 overflow 策略。 最初的实现是 queue 满了就直接丢弃新事件(put_nowait 失败就算了)。后来发现这样不对——如果消费者暂时卡住然后恢复,它看到的全是旧事件,最新的反而丢了。改成"丢旧保新"(先 get 一个旧的腾位置,再 put 新的)之后,消费者恢复后至少能看到最近的状态。
最后的思考
日志系统是那种"做了没人夸、不做会骂"的基础设施。用户不会因为你有一个漂亮的调试界面而选择你的 Agent 框架,但他们一定会因为出了 bug 无法调试而放弃它。
这套系统的设计哲学和第 6 篇讲的记忆压缩一脉相承——fail-safe 优先。日志写入失败?不崩。事件推送 queue 满了?丢旧的。SSE 连接断了?清理走人。每一个环节都在说同一句话:辅助功能不能拖累核心功能。
好的调试工具让你能"回放"Agent 的决策过程。当你打开 Web Viewer,看到第 15 轮的 request 里 messages 已经膨胀到 80 条、tools 列表有 20 个工具、模型在 thinking 里纠结了半天最后选了一个错误的工具——这时候你就知道问题出在哪了。不是代码的 bug,是上下文太长导致模型注意力分散了。然后你回去调压缩阈值,问题解决。
从第 1 篇的 agent loop 到现在的第 7 篇,每一层都在回答同一个问题:怎么让 Agent 可靠地工作。循环要稳、provider 要抽象、工具要安全、权限要可控、多智能体要隔离、记忆要压缩、调试要可观测。这些东西单独看都不难,但组合在一起就构成了一个能在真实场景下跑起来的 Agent 系统。
评论