给 Agent 设计权限系统 — 自动化与安全的博弈
Agent 系统有一个根本性矛盾:你希望它自动化程度够高,这样才好用;但你又知道 LLM 会犯错,不能什么都让它自动做。
给 Agent 跑 git status 完全没问题,但如果它突然要跑 rm -rf /,你肯定想先被问一句。问题是,这条线画在哪里?
BareAgent 的权限系统就是在处理这个矛盾。它不是一个复杂的 ACL 系统,而是一组"在执行工具之前决定要不要问用户"的规则。
四种模式:从完全信任到只读
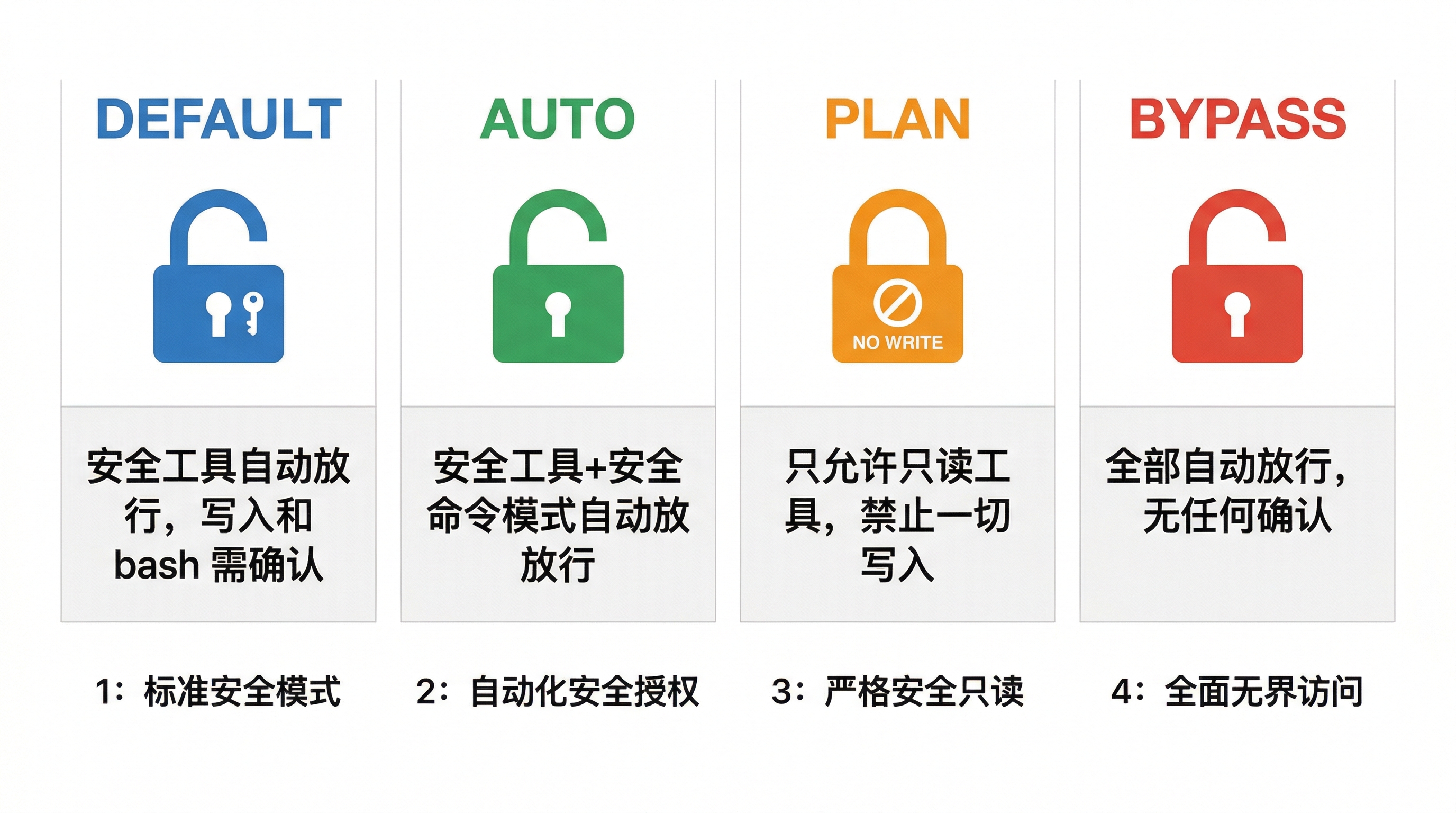
BareAgent 定义了四种权限模式,对应四种不同的信任级别:
class PermissionMode(Enum):
DEFAULT = "default" # 保守模式
AUTO = "auto" # 自动化优先
PLAN = "plan" # 只读
BYPASS = "bypass" # 完全跳过确认
| 模式 | 用法场景 |
|---|---|
| DEFAULT | 日常使用。安全操作自动放行,其他的问一下 |
| AUTO | 信任当前任务,不想被频繁打断 |
| PLAN | 只想让 Agent 看代码、做分析,别碰任何东西 |
| BYPASS | 跑测试脚本、CI 环境,完全自动化 |
实际使用下来,大部分时间在 DEFAULT 和 AUTO 之间切换。Shift+Tab 一键循环切换模式,体验上比输入命令快得多。
每种模式的核心差异在 requires_confirm() 这一个方法里:
def requires_confirm(self, tool_name, tool_input):
if self.mode == PermissionMode.BYPASS:
return False
if self.mode == PermissionMode.PLAN:
return tool_name not in self.SAFE_TOOLS
if tool_name in self.SAFE_TOOLS:
return False
if tool_name in {"edit_file", "task_create", "task_update"}:
return False
if tool_name == "write_file":
return self.mode == PermissionMode.DEFAULT
if tool_name != "bash":
return True
# bash 走特殊的命令级判断...
逻辑看起来有点绕,但背后的思路很清晰:
- BYPASS 什么都不问
- PLAN 只放行一组被认定为安全的工具
- 其他模式下,
read_file、glob、grep这些只读工具不需要确认 edit_file不需要确认(因为它是精确替换,风险可控),但write_file在 DEFAULT 下需要确认(整文件覆盖风险更大)bash最特殊——需要看具体命令内容
危险命令检测:这些必须拦住
bash 是所有工具里最危险的,因为它什么都能做。BareAgent 维护了一组正则表达式来检测高风险命令:
DANGEROUS_PATTERNS = [
re.compile(r"(^|\s)rm\s+-[rR]f?\b"), # rm -rf
re.compile(r"git\s+push\s+--force\b"), # 强推
re.compile(r"git\s+reset\s+--hard\b"), # 硬重置
re.compile(r"DROP\s+TABLE\b", re.IGNORECASE), # 删表
re.compile(r"DELETE\s+FROM\b", re.IGNORECASE), # 删数据
re.compile(rf"(^|\s)({_SHELLS})\s+-c\b"), # shell -c 绕过
re.compile(r"(^|\s)/(?:usr/)?bin/rm\b"), # 绝对路径 rm
re.compile(r"(^|\s)env\s+"), # env 前缀
re.compile(rf"curl\b.*\|\s*({_SHELLS})\b"), # curl | bash
re.compile(r"(^|\s)chmod\s+777\b"), # 开放权限
re.compile(r"(^|\s)mkfs\b"), # 格式化
re.compile(r"(^|\s)dd\s+if="), # 磁盘写入
re.compile(r"find\b.*-delete\b"), # find -delete
]
这些模式不是"禁止执行",而是"即使在 AUTO 模式下也必须先问用户"。模型想跑 rm -rf build 可以,但得先经过你同意。
有几个模式值得展开说:
shell wrapper 绕过 — bash -c "rm -rf /" 是一种常见的绕过方式。如果你只检查命令开头是不是 rm,用 bash -c 包一层就绕过去了。所以 bash -c、sh -c、zsh -c 这些都被标记为危险。
绝对路径 rm — 模型偶尔会用 /bin/rm 而不是 rm,这同样能绕过简单的前缀匹配。
env 前缀 — env rm -rf / 也能绕过只看命令开头的检测。
curl | bash — 从网上下载脚本直接管道执行,在安全领域是经典红旗。
这组规则不可能覆盖所有危险操作,但覆盖了最常见的几类。它是安全网而不是铁壁——最终的安全保障还是需要用户自己判断。
自动安全模式
除了检测危险命令,还有一组正则用来识别"可以自动放行"的安全命令:
AUTO_SAFE_PATTERNS = [
re.compile(r"^(ls|cat|head|tail|wc|echo|pwd|date|which|type)\b"),
re.compile(r"^git\s+(status|log|diff|branch|show)\b"),
re.compile(r"^(pytest|python\s+-m\s+pytest|ruff|mypy)\b"),
re.compile(r"^npm\s+(test|run\s+lint|run\s+test)\b"),
]
git status、pytest、ruff check 这些命令在任何模式下都可以自动放行。这意味着即使在 DEFAULT 模式下,Agent 跑测试、看 git 状态也不会每次弹确认框。
优先级:deny > danger > allow > safe > 模式默认
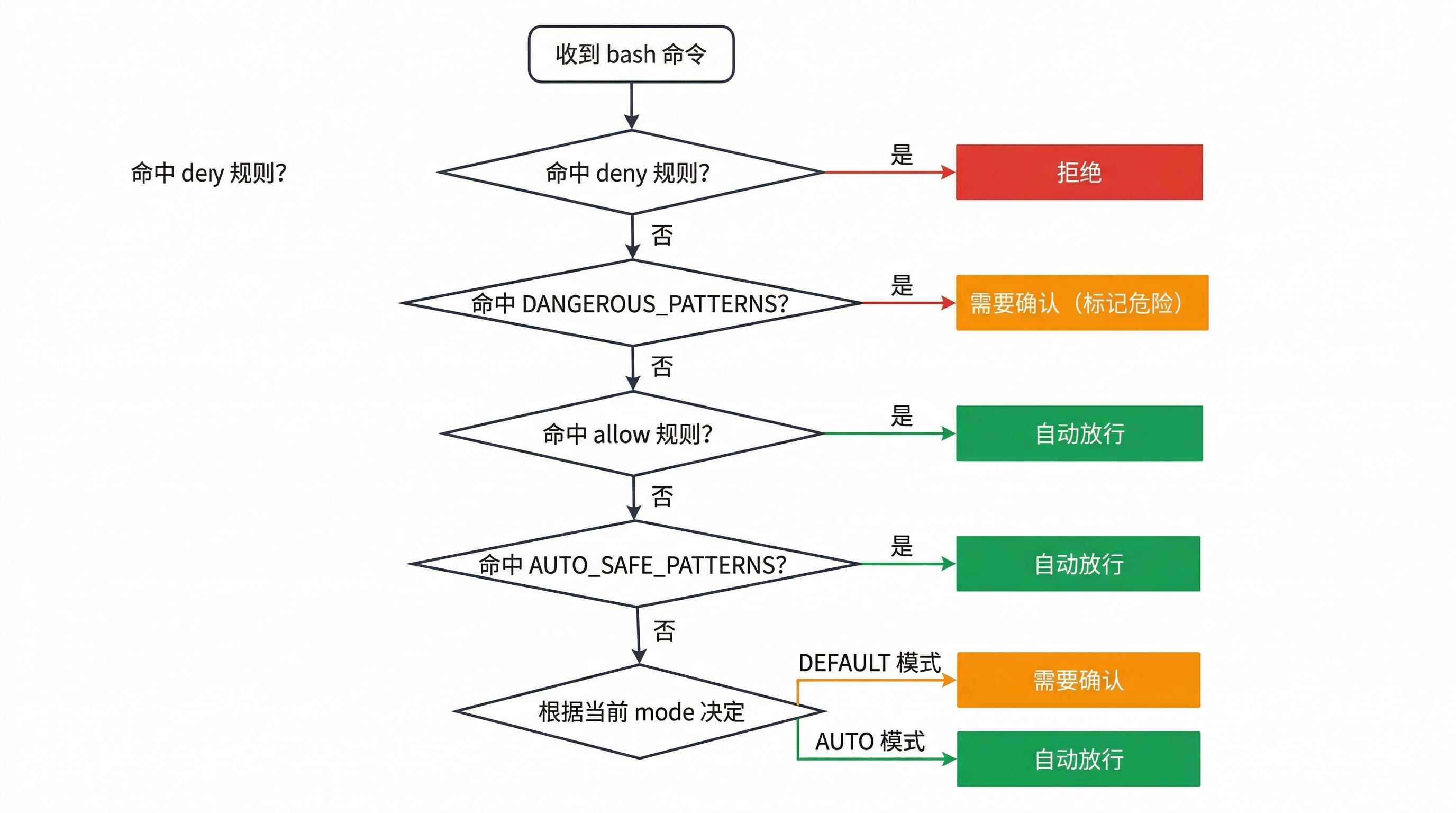
bash 命令的完整判断链条是这样的:
1. deny 规则命中 → 必须确认
2. 危险模式命中 → 必须确认
3. allow 规则命中 → 不需要确认
4. 自动安全模式命中 → 不需要确认
5. DEFAULT → 需要确认
AUTO → 不需要确认
这个优先级设计有一个很关键的特性:危险模式的优先级高于 allow 规则。也就是说你不能通过在配置里写 allow = ["bash(prefix:rm*)"] 来绕过 rm -rf 的检测。这是刻意的——我不想让用户一不小心就把安全网关掉。
Allow/Deny 规则的语法是前缀匹配:
[permission]
allow = ["bash(prefix:npm run *)"]
deny = ["bash(prefix:npm publish*)"]
这种设计足够简单,能覆盖"允许跑 npm 脚本但不许 publish"之类的场景。不需要支持完整的正则——前缀匹配已经够用了,而且更好理解。
Fail-closed:问不了就拒绝
这可能是整个权限系统里最重要的设计决策。
ask_user() 在以下情况下会直接拒绝,不是返回"默认允许":
def ask_user(self, call):
if self.fail_closed:
return False
if self.mode == PermissionMode.PLAN:
return False
if not sys.stdin.isatty():
return False
# ...实际询问用户...
fail_closed=True— 直接拒绝- PLAN 模式 — 直接拒绝(只读就是只读)
- 非交互式终端 — 直接拒绝(没有人能回答你)
- 读输入遇到 EOF — 拒绝
这叫 fail-closed——在无法确认的时候偏向拒绝而不是放行。
为什么这很重要?因为后台任务和子智能体没有可靠的人机交互通道。如果后台子智能体跑着跑着需要确认一个 bash 命令,没有人能回答它。这时候"默认允许"会让你夜里做噩梦,而"默认拒绝"最多是任务失败——失败总比搞破坏好。
子智能体的权限隔离
当主智能体启动一个子智能体时,权限不是简单继承的:
def for_subagent(self, agent_type, *, background=False):
resolved_mode = agent_type.permission_mode if agent_type.permission_mode is not None else self.mode
return self.clone(
mode=resolved_mode,
fail_closed=self.fail_closed or background or resolved_mode == PermissionMode.PLAN,
)
这里有几个关键逻辑:
- 如果 AgentType 指定了权限模式(比如
explore指定了PLAN),用它的 - 否则继承父级模式
- 如果是后台执行(
background=True),强制fail_closed - 如果最终模式是
PLAN,也强制fail_closed allow_rules和deny_rules会被复制过去
一个我犹豫过的设计选择是:要不要自动把父级的 AUTO 降成 DEFAULT?
最终决定不降级。理由是:general-purpose 子智能体继承父级 AUTO 模式是合理的——用户既然选了 AUTO,说明信任当前环境。而如果要限制子智能体能力,应该用 AgentType(比如选 explore 类型)来控制,而不是偷偷改权限模式。
运行时动态切换
权限模式不需要重启就能切换:
/default → 保守模式
/auto → 自动化
/plan → 只读
/bypass → 完全跳过
Shift+Tab → 循环切换
这在实际使用中很自然:一开始用 DEFAULT 仔细看 Agent 在做什么,确认它方向对了之后切到 AUTO 让它自己跑,需要它只做分析时切 PLAN。
踩过的坑
edit_file 要不要确认的纠结。一开始 edit_file 在 DEFAULT 下也需要确认,但用了几天发现 Agent 写代码时平均每个任务要做十几次 edit,每次都弹确认简直没法用。后来分析了一下:edit_file 是精确替换,它找不到 old_text 就会报错,不会悄悄覆盖整个文件,风险比 write_file 低得多。所以最终把它放进了"不需要确认"的类别。
危险模式的正则要足够宽泛。最开始只写了 ^rm -rf,后来发现 LLM 偶尔会写 sudo rm -rf 或者 rm -rf(带前导空格)。所以模式改成了 (^|\s)rm\s+-[rR]f?\b——匹配行首或空白之后的 rm,不管有没有大写 R。这类细节不测试根本发现不了。
非交互环境的处理。在 CI 或者 Docker 里跑 Agent 时 sys.stdin.isatty() 返回 False。一开始没处理这个 case,导致 input("Allow?") 卡死。加了 tty 检查之后,非交互环境直接 fail-closed。
延伸思考
Agent 权限是一个还在演进的领域。Claude Code 最近推出的 hooks 机制就是一种更灵活的权限控制方式——你可以在工具执行前后挂自定义脚本,比检查命令前缀要强大得多。
但我认为简单的规则对大多数用户足够了。与其给一套图灵完备的权限 DSL,不如给四种清晰的模式加一组"看得懂的"危险检测。用户能在两秒内理解"AUTO 模式下非危险命令自动放行",但很难在两秒内理解一套复杂的策略引擎。
另一个方向是和 OS 级沙箱结合。BareAgent 当前的权限检查全在应用层,理论上 LLM 如果能构造出绕过正则的命令,检查就失效了。更可靠的做法是把 Agent 跑在容器或者沙箱进程里,让 OS 层面兜底。但对于一个终端工具来说,要求用户先起一个 Docker 容器再用,门槛就太高了。所以目前这种"应用层检测 + fail-closed 兜底"的组合是一个可接受的平衡点。
评论