工具系统 — Agent 能力的边界在哪里
一个 Agent 到底有多"能干",不取决于模型多聪明,取决于你给了它什么工具。
模型再厉害,不给它 bash 工具就跑不了命令,不给它 write_file 就写不了文件。工具定义了 Agent 能力的硬边界。所以 BareAgent 的工具系统设计,本质上就是在回答一个问题:怎么告诉模型"你能做什么",同时控制它"实际怎么做"。
两层分离:Schema 和 Handler
BareAgent 把工具拆成了两层,这个分离在一开始并不是设计出来的,而是写着写着自然演变的:
- Schema — 告诉 LLM "你有什么工具可以用,每个工具接受什么参数"
- Handler — 在运行时真正执行这些工具
Schema 通过 get_tools() 获取,返回一个字典列表:
{
"name": "bash",
"description": "Run a shell command in the current workspace.",
"parameters": {
"type": "object",
"properties": {
"command": {"type": "string", "description": "Command to execute."},
"timeout": {"type": "integer", "description": "Timeout in seconds.", "default": 30}
},
"required": ["command"]
}
}
Handler 通过 get_handlers(workspace) 获取,返回一个 {工具名: 可调用对象} 的映射:
handlers = {
"bash": partial(run_bash, cwd=workspace),
"read_file": partial(run_read, workspace=workspace),
"write_file": partial(run_write, workspace=workspace),
...
}
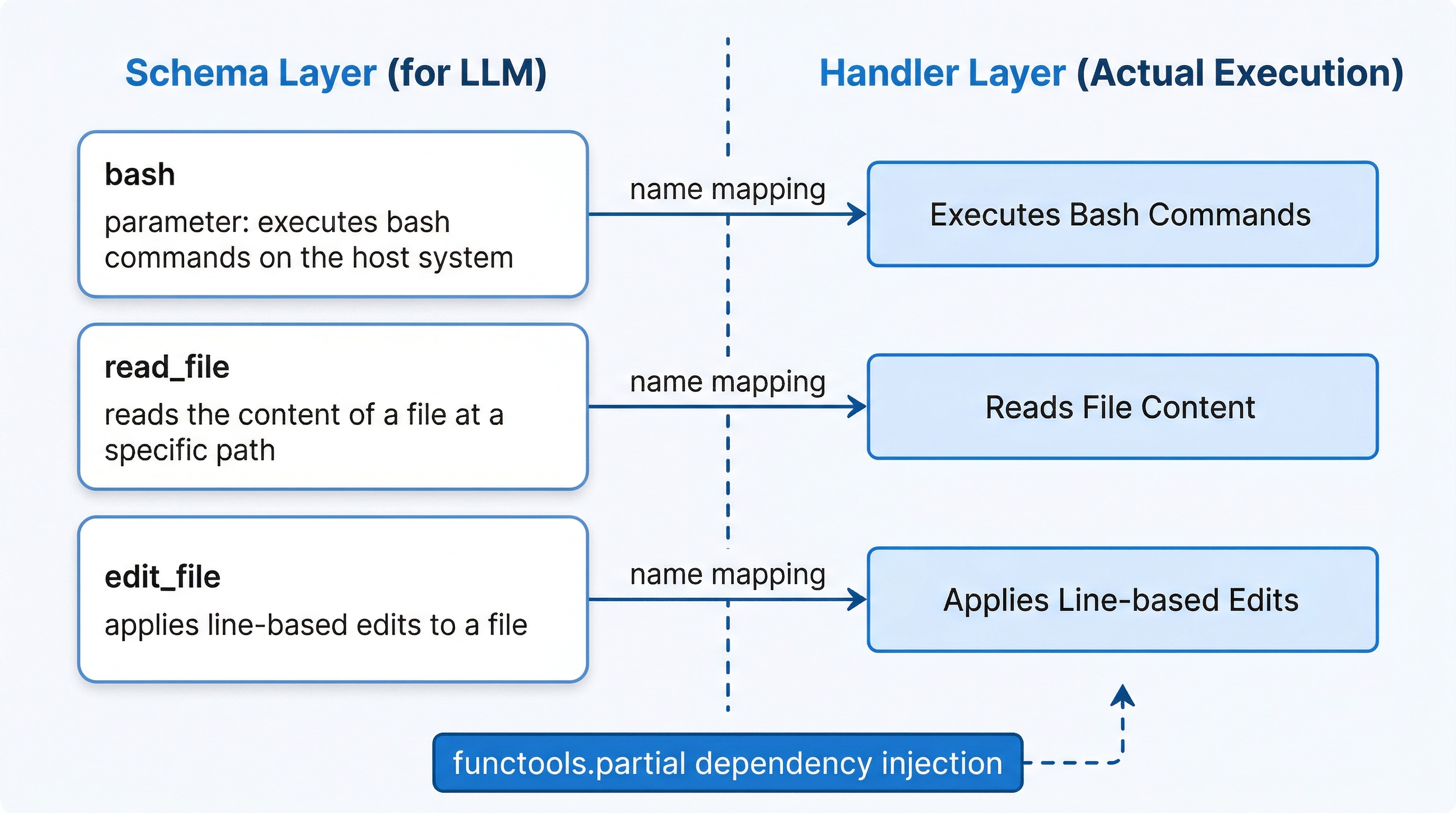
这两层的分离意味着:schema 可以在不初始化运行环境的情况下生成。你甚至可以在没有 workspace 的时候就知道"系统有哪些工具可用",只是不能执行而已。
这在子智能体场景下特别有用——我需要根据 agent 类型对工具列表做过滤,而过滤只需要操作 schema,不需要动 handler。
functools.partial 做依赖注入
Handler 的绑定用了 functools.partial,这是整个工具系统里我最满意的一个选择:
handlers = {
"bash": partial(run_bash, cwd=workspace),
"read_file": partial(run_read, workspace=workspace),
"write_file": partial(run_write, workspace=workspace),
"edit_file": partial(run_edit, workspace=workspace),
"glob": partial(run_glob, workspace=workspace),
"grep": partial(run_grep, workspace=workspace),
}
每个 handler 函数本身是纯粹的——run_bash(command, timeout, cwd) 不依赖任何全局状态。partial 把 cwd=workspace 提前绑进去,返回一个只需要 command 和 timeout 参数的函数。
这比用类继承或者依赖注入容器要轻量得多。一个 partial 就解决了"运行时依赖"和"接口参数"的分离问题。而且测试起来极其方便——给一个临时目录就能造一套完整的 handler 出来。
延迟加载:不是所有工具都需要一开始就准备好
BareAgent 有两组工具:基础工具(bash、文件操作、搜索)和延迟加载工具(todo、task、subagent、skill 等)。
名字叫"延迟加载",但需要准确理解它延迟的是什么:
- Schema 从一开始就全量暴露给模型,不管你用不用
subagent,模型都能看到它 - 延迟的是 manager 和 handler 的初始化
比如 TaskManager,它需要读写 .tasks.json 文件,但如果这个会话根本没用到任务功能,就不需要初始化它。所以 BareAgent 用了一个懒加载包装器:
def _make_lazy_task_handlers(task_file):
state = {"handlers": None}
def _get_handlers():
if state["handlers"] is None:
state["handlers"] = make_task_handlers(TaskManager(task_file))
return state["handlers"]
return {
"task_create": lambda title, **kw: _get_handlers()["task_create"](title=title, **kw),
"task_list": lambda status=None: _get_handlers()["task_list"](status=status),
...
}
第一次调用 task_create 的时候才会实例化 TaskManager,后续调用复用同一个实例。这种模式让启动更快,也避免了在不需要的场景下创建无用的文件。
TodoManager 和 SkillLoader 用了类似的单例模式,不过额外加了线程锁,因为后台子智能体可能在另一个线程里触发初始化:
_SINGLETON_LOCK = threading.Lock()
def _get_default_todo_manager():
global _DEFAULT_TODO_MANAGER
if _DEFAULT_TODO_MANAGER is None:
with _SINGLETON_LOCK:
if _DEFAULT_TODO_MANAGER is None:
_DEFAULT_TODO_MANAGER = TodoManager()
return _DEFAULT_TODO_MANAGER
经典的双重检查锁。在 Agent 系统里你得时刻记住:后台执行意味着多线程。
沙箱:LLM 不能随便乱访问文件系统
给 LLM 一个文件操作工具,最先想到的安全问题就是:它会不会通过 ../../etc/passwd 这种路径跑出 workspace?
safe_path() 就是干这个的:
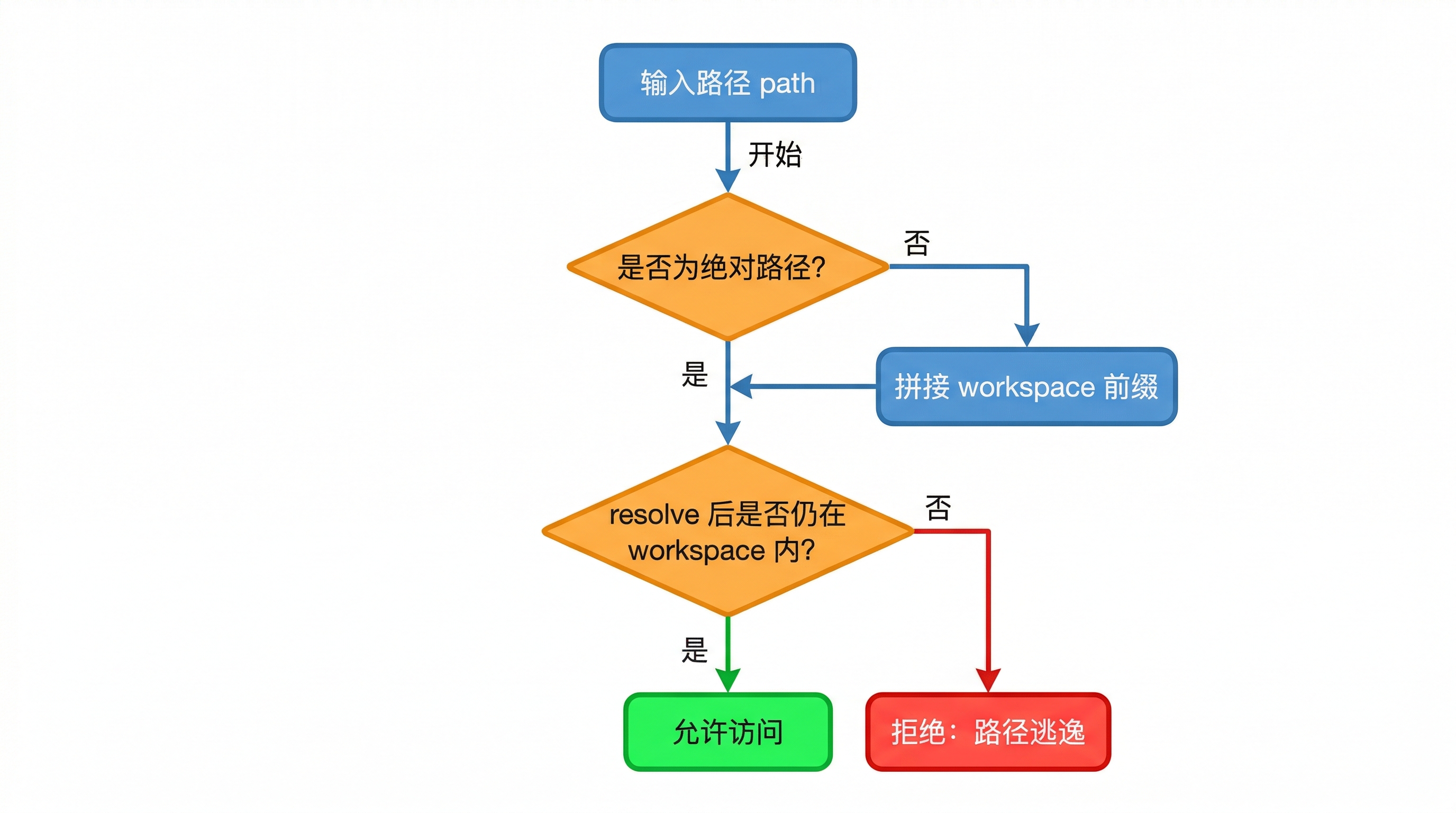
def safe_path(path: str, workspace: Path) -> Path:
if path.startswith("~"):
raise PermissionError(f"Home-relative paths are not allowed: {path!r}")
candidate = Path(path)
if candidate.is_absolute():
raise PermissionError(f"Absolute paths are not allowed: {path!r}")
resolved = (workspace / candidate).resolve(strict=False)
if not resolved.is_relative_to(workspace):
raise PermissionError(f"Path {path!r} escapes workspace {workspace}")
_check_no_symlink_in_chain(workspace, candidate)
return resolved
它做了四件事:
- 拒绝
~开头的路径(home 目录) - 拒绝绝对路径
- resolve 之后检查是否还在 workspace 内部(防
..逃逸) - 逐级检查路径链上有没有符号链接
第四点容易被忽略:如果 workspace 里有个符号链接指向外部目录,不检查的话 resolve() 可能解析到 workspace 外面去。所以 _check_no_symlink_in_chain() 会沿着路径每一级走一遍:
def _check_no_symlink_in_chain(workspace, candidate):
current = workspace
for part in candidate.parts:
current = current / part
if current.is_symlink():
raise PermissionError(f"Symlink detected in path chain: {current}")
这种防御不是 paranoia——在实际使用中,LLM 偶尔确实会尝试用 ../ 去读它不该读的文件。不是恶意,只是模型有时候会"脑补"出一些它认为存在的路径。
工具处理器的实现细节
几个基础工具的实现有些有意思的设计选择:
bash 在 Windows 下用 powershell -NoProfile -Command,非 Windows 下用 bash -lc。返回值不区分 stdout 和 stderr,全部合并成一个字符串。这是刻意的——模型不需要知道某段输出是 stderr 还是 stdout,它只需要看到命令跑完之后"发生了什么"。
grep 有个 1MB 的文件大小限制和 1000 条匹配上限。不加这个限制的话,一次搜索可能返回几兆的文本,直接把上下文窗口撑爆。搜索结果格式是 文件路径:行号:匹配行,和 ripgrep 的默认输出类似,模型很容易理解。
glob 和 grep 都会自动跳过 .git、node_modules、__pycache__ 这些目录。不跳的话搜索结果里满是噪音。不过如果你显式指定了 path=".venv",它会尊重你的选择继续搜索。
edit_file 只做文本级的精确替换(第一次出现的 old_text → new_text),不是 AST 级编辑。这个决定是刻意的——AST 编辑听起来高级但太脆了,不同语言需要不同的 parser。纯文本替换足够通用,模型也很擅长生成精确的文本差异。
get_handlers() 的丰富度
看看 get_handlers() 的完整签名就知道工具系统承载了多少运行时依赖:
def get_handlers(
workspace,
*,
todo_manager=None,
task_manager=None,
skill_loader=None,
provider=None,
tools=None,
permission=None,
bg_manager=None,
subagent_system_prompt="",
subagent_max_depth=3,
subagent_default_type="general-purpose",
team_handlers=None,
subagent_depth=0,
) -> dict[str, Callable]:
同一个工具 schema,在不同运行环境下可能绑定出完全不同的能力:
- 没有 provider →
subagent退化为"不可用" - 没有
BackgroundManager→background_run退化为"不可用" - 没有 team handlers →
team_*返回空 stub
这种"优雅退化"比"硬性要求"好得多。你可以在最简配置下跑一个只有基础工具的 Agent,也可以在完整 REPL 里拥有全部能力。
延伸思考
做完工具系统之后,最大的体会是:工具的设计质量直接决定了 Agent 的实际效果。
比如 read_file 的返回格式——加行号是为了让模型引用具体位置,用 12: line content 这种格式是因为模型对这种格式的理解最好。如果返回没有行号的纯文本,模型在做 edit 的时候就会频繁出错。
再比如 bash 不区分 stdout/stderr,grep 限制 1000 条结果,glob 跳过缓存目录——这些都不是"正确的工程选择",而是"让模型好用的选择"。工具的受众是 LLM,不是人类。
业界的 Agent 框架(比如 Claude Code、Cursor)也在朝这个方向走:工具不只是 API 的封装,更是为 LLM 量身定制的能力接口。参数命名、返回格式、错误信息,每一个细节都在影响模型的行为质量。
另一个值得思考的方向是工具的粒度。BareAgent 当前的 6 个基础工具粒度比较粗——一个 bash 可以做任何事。如果拆成 run_test、run_linter、install_package 之类的细粒度工具,模型会更容易选对工具,但维护成本也更高。这是一个需要持续权衡的设计决策。
评论