适配多家大模型 API — 抽象层设计实践
做 Agent 系统时,一个绕不开的问题是:你到底要绑死在哪家模型上?
BareAgent 一开始就想支持多家 LLM——至少 Anthropic 和 OpenAI 要能切换。听上去不难,不就是封装个接口嘛。但真正动手之后才发现,两家的 API 差异比我预想的要大得多,而且"差异在哪里"这件事本身就不太直观。
差异到底有多大
先举几个具体的例子。
消息格式:Anthropic 把 system prompt 作为一个独立的顶层参数,而 OpenAI 是放在 messages 数组里作为 role: "system" 的消息。
工具定义:Anthropic 用 input_schema,OpenAI 用嵌套的 function.parameters:
# Anthropic 的工具格式
{"name": "bash", "description": "...", "input_schema": {"type": "object", ...}}
# OpenAI 的工具格式
{"type": "function", "function": {"name": "bash", "description": "...", "parameters": {"type": "object", ...}}}
工具调用结果的回传:Anthropic 要求放在 role: "user" 消息里作为 tool_result block;OpenAI Chat Completions 则需要单独的 role: "tool" 消息。
流式协议:Anthropic 的 content_block_delta / content_block_stop 和 OpenAI 的 delta.content / delta.tool_calls 完全是两套事件模型。
这些差异零零碎碎,没有一个是"难"的,但加起来就很繁琐。如果在 agent 循环里到处写 if provider == "anthropic" 那代码会变得不可维护。
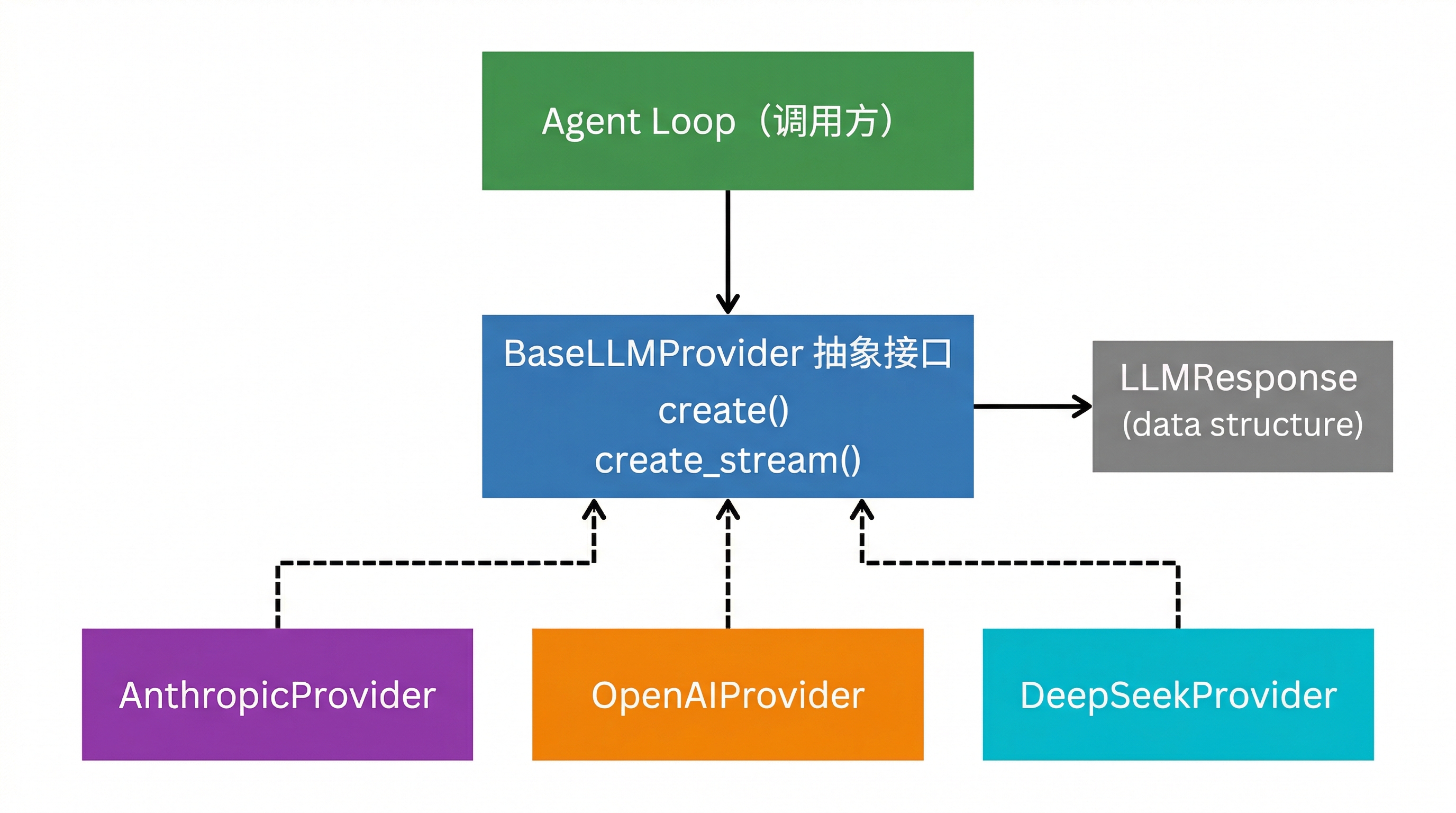
统一抽象:BaseLLMProvider 和 LLMResponse
解决方案很经典——抽象基类加统一响应结构:
class BaseLLMProvider(ABC):
@abstractmethod
def create(self, messages, tools, **kwargs) -> LLMResponse: ...
@abstractmethod
def create_stream(self, messages, tools, **kwargs) -> Generator[StreamEvent, None, LLMResponse]: ...
上层只需要关心两个方法:create() 给我一个完整响应,create_stream() 给我一串事件流加最终响应。
而 LLMResponse 是所有厂商响应的归一化表示:
@dataclass(slots=True)
class LLMResponse:
text: str # 文本输出
stop_reason: str # 终止原因
input_tokens: int # 输入 token
output_tokens: int # 输出 token
tool_calls: list[ToolCall] = field(...) # 归一化工具调用
thinking: str = "" # 思考内容(仅 Anthropic)
content_blocks: list[dict] = field(...) # 细粒度块结构
不管底层来自 Anthropic 的 tool_use block 还是 OpenAI 的 tool_calls 数组,上层拿到的永远是:
ToolCall(id="...", name="bash", input={"command": "ls"})
这样 agent_loop() 就完全不需要知道当前用的是哪家模型了。token 计数也一样——Anthropic 叫 input_tokens,OpenAI 叫 prompt_tokens,归一化之后都是 LLMResponse.input_tokens。
Anthropic 适配
Anthropic 的适配相对直接,因为 BareAgent 内部的消息格式本身就比较接近 Claude Messages API。主要的转换工作是:
- 把
role: "system"的消息抽出来合并成一个system字符串参数 - 把内部的
parameters格式工具定义转成input_schema - 处理 thinking block 的保留和回传
Anthropic 独有的一个特性是 extended thinking。BareAgent 通过 ThinkingConfig 来控制:
if self.thinking_config.mode in {"enabled", "adaptive"}:
params["thinking"] = {
"type": self.thinking_config.mode,
"budget_tokens": self.thinking_config.budget_tokens,
}
max_tokens = max(max_tokens, self.thinking_config.budget_tokens + 1)
这里有个细节:max_tokens 必须大于 budget_tokens,否则 API 会报错。所以代码里做了个 max() 来保证这个约束。
流式方面,Anthropic 的 SDK 提供了 client.messages.stream() 上下文管理器,用起来比较顺畅。不过工具调用事件的时机需要注意——它不是在 delta 里分段发的,而是在 content_block_stop 事件里一次性给完整的工具调用信息:
if event.type == "content_block_stop":
content_block = event.content_block
if content_block.type == "tool_use":
yield StreamEvent(
type="tool_call",
tool_call_id=content_block.id,
name=content_block.name,
input=dict(content_block.input or {}),
)
OpenAI 适配:两套 API 的兼容
OpenAI 的情况更复杂一些,因为它现在有两套 API 了。
Chat Completions 是经典的那套,消息格式用 messages 数组,工具用 function wrapper,流式事件是 chunk 里的 delta。
Responses API 是新的那套,系统消息变成了 instructions,工具调用变成了 function_call,工具结果变成了 function_call_output,流式事件也是另一套模型。
BareAgent 通过一个 wire_api 参数来区分走哪条路径:
def create(self, messages, tools, **kwargs):
if self.wire_api == "responses":
return self._create_via_responses(messages, tools, **kwargs)
params = self._build_chat_request_params(messages, tools, **kwargs)
response = self.client.chat.completions.create(**params)
return self._parse_response(response)
两条路径的消息转换逻辑差异不小。比如 Chat Completions 里 tool result 要变成 role: "tool" 消息:
{"role": "tool", "tool_call_id": "...", "content": "..."}
而 Responses API 里则是:
{"type": "function_call_output", "call_id": "...", "output": "..."}
连字段名都不一样(tool_call_id vs call_id,content vs output)。
流式的拼接问题
Chat Completions 的流式工具调用有个特别烦人的地方:工具参数是分段发的。你会在连续的 chunk 里收到 delta.tool_calls[0].function.arguments 的片段,需要自己拼起来:
for tool_delta in delta.tool_calls or []:
call_state = pending_tool_calls.setdefault(
tool_delta.index,
{"id": "", "name": "", "arguments": ""},
)
if tool_delta.id:
call_state["id"] = tool_delta.id
if function.arguments:
call_state["arguments"] += function.arguments
这意味着你需要维护一个 pending_tool_calls 字典,按 index 累积参数片段,等到 finish_reason == "tool_calls" 或者流结束时再把它们 finalize 成完整的 ToolCall。
Responses API 的流式就友好一些——它在 response.output_item.done 事件里直接给完整的工具调用信息,不需要拼接。
参数解析的防御
OpenAI 返回的工具参数是 JSON 字符串,需要 parse。但不能假设它永远是合法 JSON:
def _parse_tool_input(self, arguments: str) -> dict:
try:
parsed = json.loads(arguments)
except json.JSONDecodeError:
parsed = {"raw_arguments": arguments}
if not isinstance(parsed, dict):
parsed = {"value": parsed}
return parsed
JSON 解析失败就退化成 {"raw_arguments": "..."};解析出来不是 dict(比如模型返回了一个纯数组)就再包一层。总之上层拿到的永远是 dict[str, Any],不会因为模型的奇怪输出而崩掉。
工厂模式:一行配置切换模型
有了两个具体 provider 之后,还需要一个工厂把配置翻译成实例:
def create_provider(config) -> BaseLLMProvider:
if provider_name == "anthropic":
return AnthropicProvider(api_key=api_key, model=model, thinking_config=...)
if provider_name == "openai":
return OpenAIProvider(api_key=api_key, model=model, base_url=..., wire_api=...)
if provider_name == "deepseek":
return OpenAIProvider(api_key=api_key, model=model, base_url=DEEPSEEK_BASE_URL, ...)
DeepSeek 直接复用了 OpenAIProvider——因为它兼容 OpenAI Chat Completions 协议,只需要改个 base_url。这也是为什么 provider 层要支持自定义 base_url 参数的原因,很多第三方模型服务都走 OpenAI 兼容接口。
API key 的处理也有个小设计:配置文件里存的是环境变量名而不是密钥本身:
api_key_env = getattr(provider_config, "api_key_env", "")
api_key = os.getenv(api_key_env)
这样配置文件可以安全地提交到 git,不用担心泄露密钥。
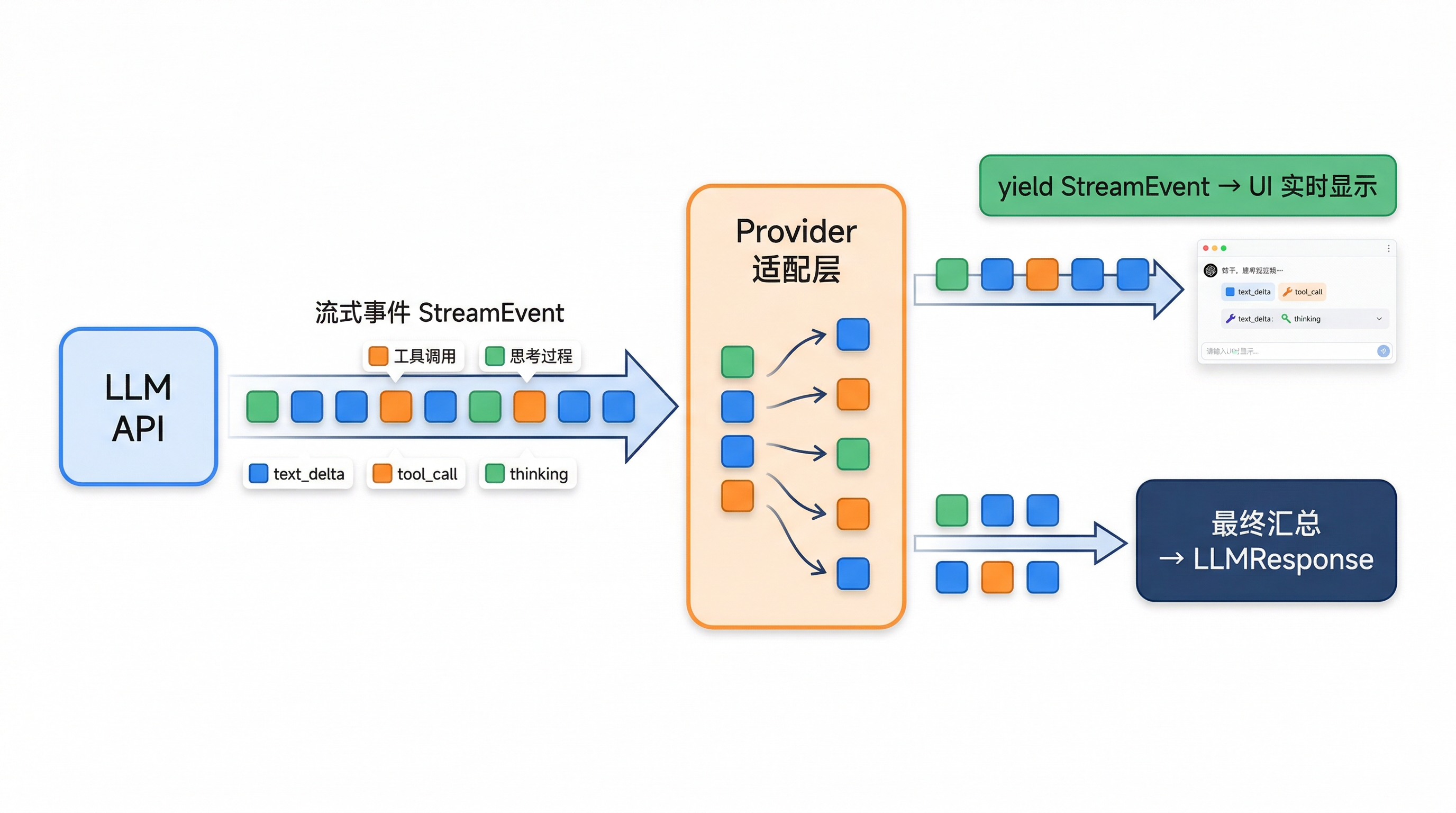
流式 vs 非流式的统一
两条调用路径的最终目标是一致的:都返回 LLMResponse。差异只是流式路径多产出一串 StreamEvent。
BareAgent 的 create_stream() 用了 Python generator 的 return value 特性——yield 吐事件,return 给最终响应。这让流式和非流式在上层消费时的差异最小化。
一个有趣的设计选择是:如果流式不可用(provider 不支持或者出错了),系统会自动回退到非流式,而不是报错。但前提是流还没开始吐任何内容:
if not saw_stream_event and _is_streaming_unsupported(exc):
raise _StreamingUnavailableError() from exc
一旦已经输出了部分文本,中途断掉就不能静默回退了——那时候用户已经看到了一半的输出,偷偷切换会造成混乱。
踩过的坑
OpenAI 官方 API 和兼容接口的微妙差异。比如 stream_options={"include_usage": True} 在官方 API 上能用,但有些兼容接口不认这个参数。所以代码里做了一个 host 检查:
if "stream_options" not in params and self._is_openai_official_api():
params["stream_options"] = {"include_usage": True}
只有确认是官方 api.openai.com 才加这个参数。看起来是小事,但不做这个判断的话,接第三方服务时会莫名其妙地报错。
thinking block 的序列化和反序列化。Anthropic 的 thinking block 带有 signature 字段,回传时必须原样保留。如果丢了 signature,API 会拒绝请求。所以 content_blocks 这个字段就是为了原样保留这些细粒度结构的。
tool_call_id 缺失问题。有些第三方兼容接口返回的工具调用不带 id,这在正常 OpenAI API 里不会发生,但兼容接口嘛……只能自动补一个 fallback id:
if not tool_call.id:
tool_call.id = f"_fallback_{next(OpenAIProvider._fallback_counter)}"
延伸思考
做完这层抽象之后回头看,我觉得 LLM provider 抽象最核心的价值不在于"支持多家模型",而在于把协议差异从业务逻辑里隔离出去。
agent 循环不需要知道 Anthropic 的 system prompt 是顶层参数、OpenAI 的是 messages 里的一条消息。压缩器不需要知道 Responses API 的 token 字段叫 input_tokens 而 Chat Completions 叫 prompt_tokens。UI 层也不需要知道 Anthropic 的流式事件和 OpenAI 的完全是两套。
这种隔离让每个模块都可以独立演进。加一个新 provider?只要实现 create() 和 create_stream(),确保输出符合 LLMResponse 的契约就行。上层一行代码都不用改。
当然,这种抽象也有限度。比如 Anthropic 的 extended thinking 是它独有的能力,强行统一到接口里反而会让抽象变得臃肿。所以 ThinkingConfig 只在 Anthropic provider 里真正生效,OpenAI provider 会直接忽略它。有时候承认差异,比强行统一更合理。
评论